< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
抱抱脸模型TOP榜,我现在只服yuxinlu1
量子位 | 公众号 QbitAI
一位个人开发者,竟然在一众大厂中,杀进了抱抱脸Models Trending榜的前排?!
这是普通的一天,我也普通地刷着抱抱脸的Trending榜。
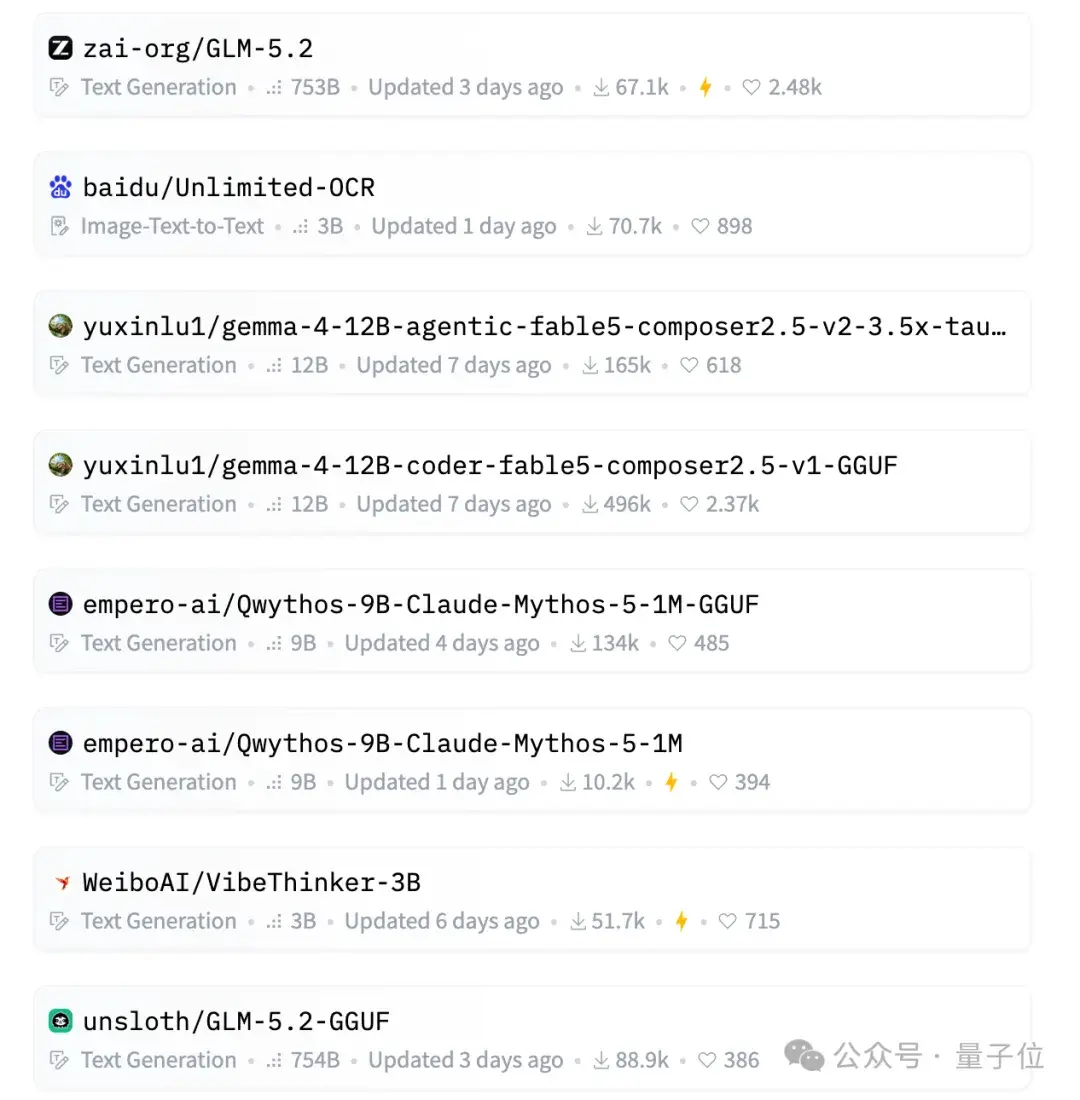
第一是GLM-5.2,智谱最新开源模型,老熟人了,下载量6万多,不足为奇。
第二是百度的无限OCR,最近悄悄开源的,一口气能解析40多页文档,下载量也来到了7万。
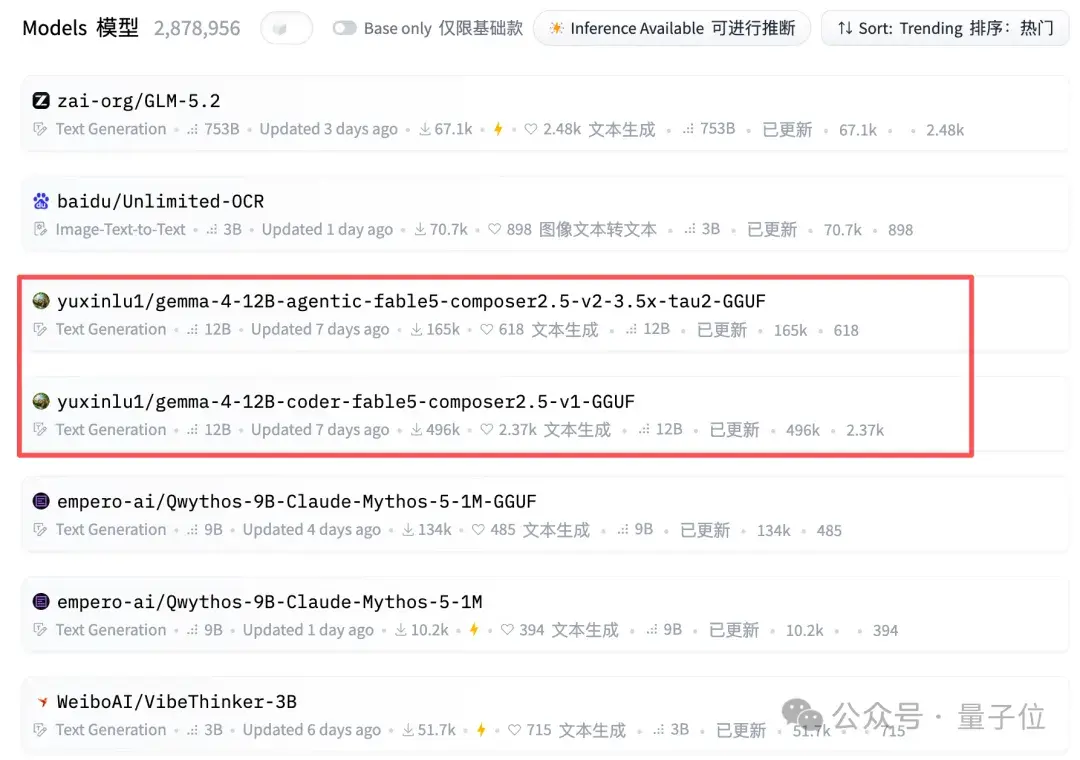
再往下看,突然出现了一个个人账号:
而且一占就是两个位置。
再一看下载量——最新数据已高达
。好家伙,这是什么神仙模型来了?
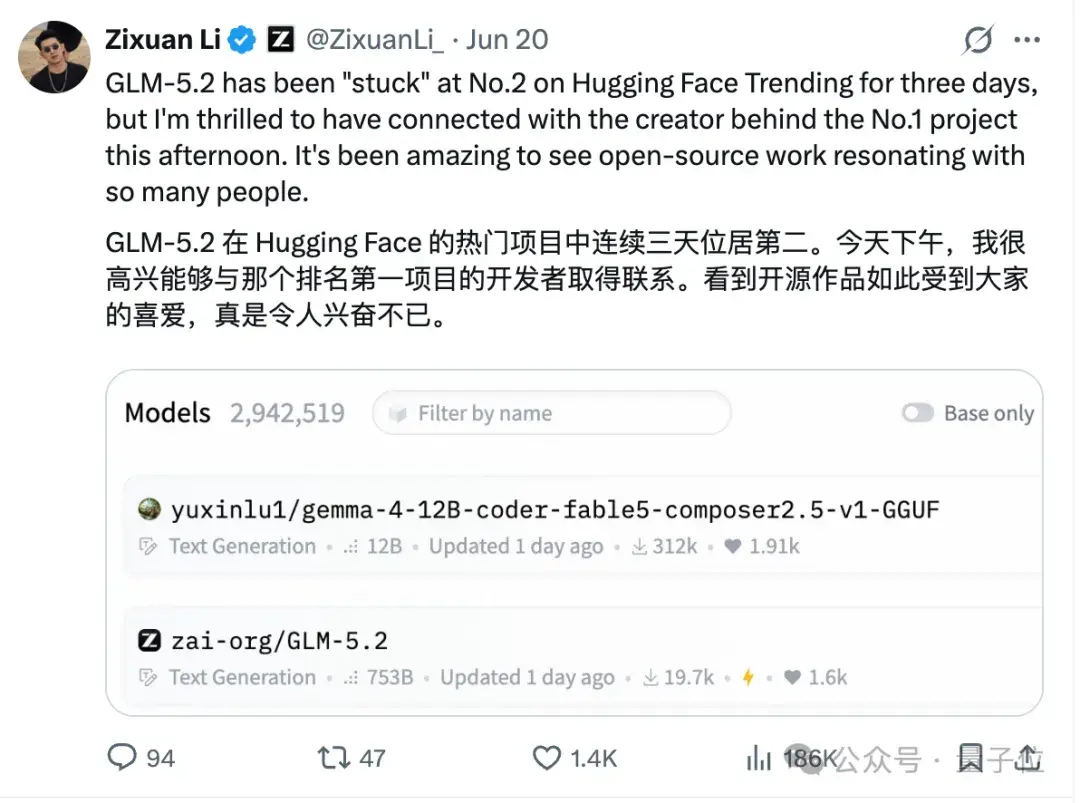
甚至在此前一周,这位个人开发者的模型一度霸榜抱抱脸,力压GLM-5.2一头,连智谱负责人都在X上公开推荐:
也就是说,在智谱、百度、Qwen、NVIDIA…这些名字中间,一个个人开发者账号硬生生挤进了TOP,而且下载量还这么高。
luyuxin究竟是谁?怎么能量这么大?
“素人模型”冲上抱抱脸热榜
这波Hugging Face热榜,前排基本是大厂、明星团队和热门赛道在卡位。
比如智谱GLM-5.2,753B超大参数,国产明星大模型;百度Unlimited-OCR,踩中了最近很火的OCR和文档理解方向。
再往下还有Qwen的AgentWorld、英伟达的 LocateAnything、微软的FastContext。
国产开源大模型的熟面孔也都在列:MiniMax M3、Kimi-K2.7-Code、DeepSeek-V4-Pro。
图像生成方向也有Krea,新模型Krea-2-Turbo和Krea-2-Raw都在榜上。
luyuxin的12B GGUF模型
luyuxin你也太醒目了吧…
仔细一看,这两个新模型,主要把
的编程推理能力,蒸进了一个本地能跑的
4.5GB显存就能跑,本地、离线、零API成本。普通玩家一张消费级显卡,甚至一台带统一内存的Mac,就能把它跑起来。
两个模型的分工也不同。
,主打写代码、解题、生成可运行代码。
据模型卡,它的训练数据是“可验证”的代码推理:每条思维链对应的代码,都得真跑过测试、通过了才留下。
教师数据主要来自Cursor的
Composer 2.5
——Composer 2.5做错的题,会交给Fable 5重新推一遍,生成新的推理链和正确代码。
V1发布后,曾连续多日霸榜抱抱脸Trending榜榜首。
V2是agentic版,加了多步工具调用能力,能当本地Agent用,会自己读、推理、动手、再验证。
作者还跑了benchmark——在tau2-bench的telecom子集上,基座gemma-4-12B得分15%,V2版模型得分55%,大概是基础性能的
不过作者也表示,这是本地自测、单一领域、20个任务跑出来的相对值,不能跟官方榜直接比,他也坦白跟frontier大模型还有不小差距。
作者还提到:Fable 5后来被下线了,只有他自己的数据集还保留着Fable 5“原始”的那份推理过程。
而社区贡献数据里缺失的那部分reasoning,他改用Claude Opus 4.8(xhigh)重新生成、一条条补了回来。
他也承认,重建出来的轨迹“可能和原版Fable 5有出入”,但这是当时唯一可行的方案。
他还在discussion里透露,这套微调数据其实只有约1万条examples。他强调,数据量没有大家想象得那么重要,真正关键的是质量、筛选和验证。
这套模型之所以能在抱抱脸上有这么高的热度,还有一个很现实的原因: