
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
英伟达开始搞机器人自己研究机器人那套了…
为了让你烧token,英伟达已经卷到机器人身上了
henry 发自 凹非寺
量子位 | 公众号 QbitAI
好好好,又给英伟达这家伙,找到了新的烧token的方式(doge)
刚刚,英伟达、CMU和Berkeley联合推出具身智能Autoresearch框架——
简单来说,ENPIRE就是让AI agent自己做机器人研究,让8个Coding Agent,各自控制一台双臂机器人。
Agent们会自己读论文、改算法、训练策略、部署实验、分析结果、总结经验,不满意再换个思路重来。
GEAR的研究员们不用盯着屏幕调参数,只需要第二天早上过来看报告。
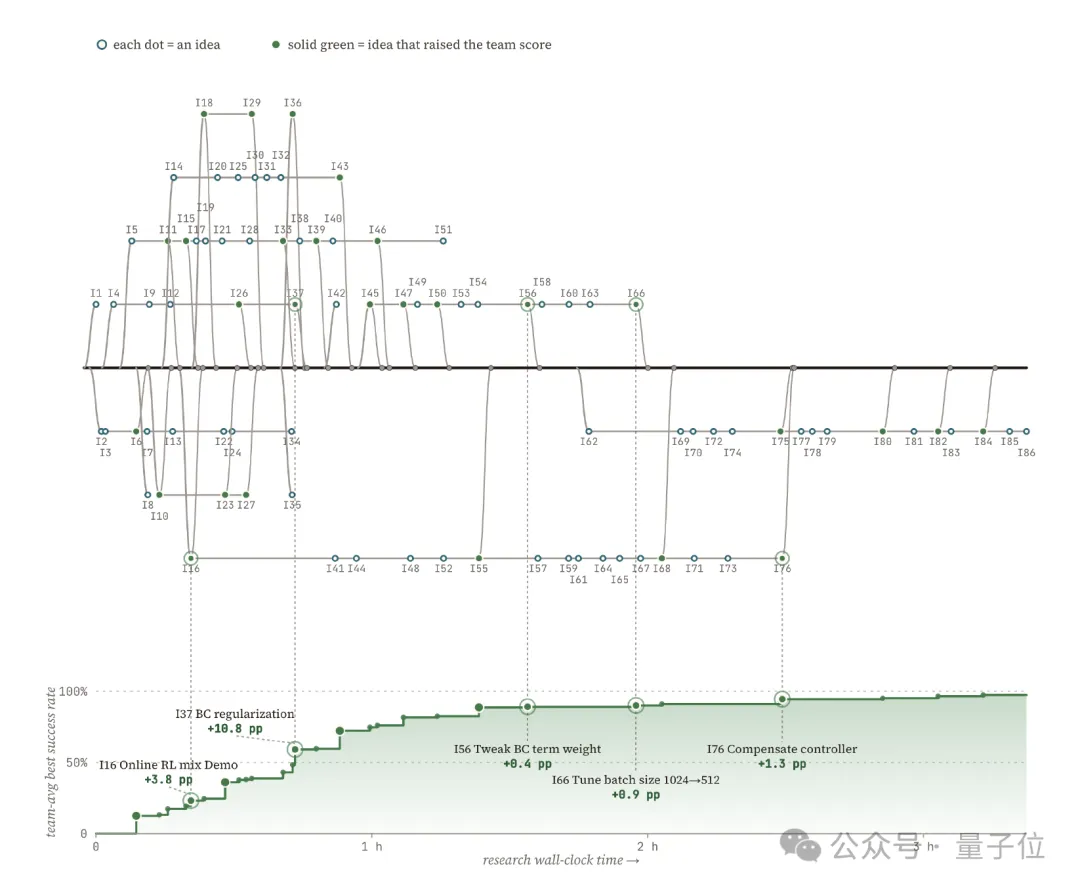
在最具代表性的Pin Insertion任务中,仅用了3小时,机器人把针插进4毫米孔洞的成功率从0一路拉到99%。
全程无人类参与,项目负责人之一的
GEAR实验室的一部分现在已经在彻夜自我改进了。我们只需要早上来读报告。
高情商:彻夜自我改进;低情商:没日没夜的烧token。
具身智能研究的harness
先说明一点,ENPIRE并不是让Agent直接写控制代码操纵机器人,它更像一个机器人研究员,需要在真实世界里重置实验场景、检索文献、实施想法、验证结果、分析问题,优化下一轮迭代。
与类似code as policy的方法不同,ENPIRE的最终产物的不是一段控制脚本,而是一个真正能够部署到机器人上的Policy。
这种给现实环境搭建自动化框架的事儿,之所以难是因为现实世界不像代码世界。
在代码世界,Agent写错代码了,大不了删掉重来;实验跑崩了,重新启动即可。
但机器人研究不一样,实验失败之后,物体会歪掉,场景会乱掉,机器人甚至可能把东西碰飞。
如果每轮实验都要靠研究员手动复位、记录结果、整理数据,那么Agent根本不可能24小时连续做研究。
所以ENPIRE做的事情,本质上是给AI研究员搭建一套自动化实验台。
Harness Framework
可以理解为,它给Coding Agent配齐了一整套做物理实验所需的基础设施。
这套基础设施由四部分组成,也正好对应ENPIRE这个名字:
EN(Environment)环境模块
:负责搭建实验环境,包括安全边界、自动复位和自动评分。
PI(Policy Improvement)策略改进
:Agent根据任务目标提出新方案。行为克隆、强化学习、启发式规则,甚至几种方法混搭,全都可以尝试。
R(Rollout)——部署测试
:把新策略部署到真实机器人上执行,记录轨迹、视频和传感器信号。
E(Evolution)——进化
: 多Agent协作的核心。8个Agent各自占用一台机器人,通过Git共享代码,互相吸收有效方案,淘汰失败路线。
四个模块连起来之后,就形成了一个完整闭环:
提出想法 → 训练策略 → 真机测试 → 自动评分 → 总结经验 → 再提出新想法。
整个过程不需要人工值守,Agent自己负责做实验,也自己负责从实验里学习。
而其中最关键的一环,其实是Environment模块。因为它解决的是具身智能研究里最令人头疼的问题:
怎么让实验自动跑起来。
在仿真环境里,复位往往只需要一句:env.reset()
但现实世界没有env.reset()。