< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
4步出声,单卡0.24秒!Noiz AI联合港科大清华,开源音频生成大模型
量子位 | 公众号 QbitAI
“先来一段蝉鸣,然后吉他声切入。”
对于这样一段看似简单的文字指令,现有的音频大模型不仅
(搞错顺序或数量),而且
(生成10秒声音,往往需要等待几秒甚至十几秒)。
这成了AI音频从“玩具”走向专业工作流和实时交互的最大绊脚石。
为了解决这一行业痛点,
Noiz AI联合香港科技大学、清华大学
等机构,正式推出了支持Anything-to-Audio的极速音频生成大模型
AudioX-Turbo
AudioX-Turbo不仅仅是一个能处理多种模态输入的生成器,更是将矛头直指
通过分布匹配蒸馏和对抗蒸馏,AudioX-Turbo将原本50-200步的扩散生成过程暴减至4步
,模型前向次数骤降约25倍;
再配合全新标注的920万量级“强指令”语料,模型终于“听懂了时间戳”。
而且,推理代码、训练代码、模型权重等
论文与项目页面:https://zeyuet.github.io/AudioX-Turbo/
项目代码:https://github.com/NoizAI/AudioX-Turbo
核心突破一:用4步打败100步,单卡0.24秒出声
现有的主流音频模型,如MMAudio,Stable Audio Open,它们多依赖Diffusion(扩散)或Flow Matching,通常需要几十到上百步迭代。
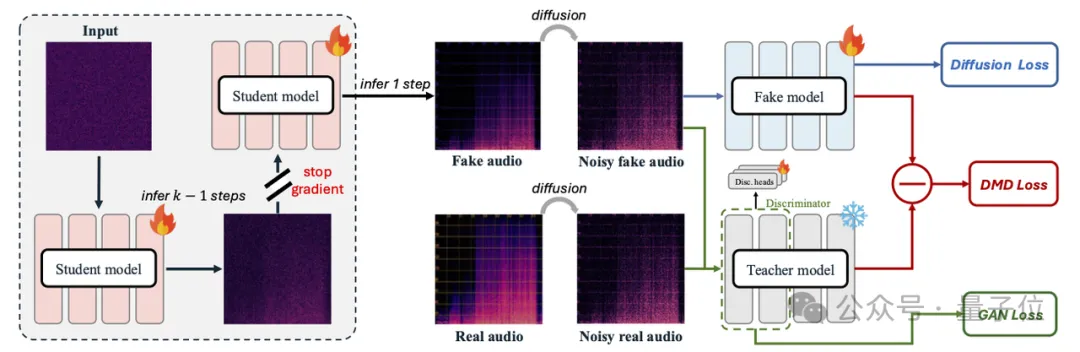
AudioX-Turbo的解法是分布匹配对抗
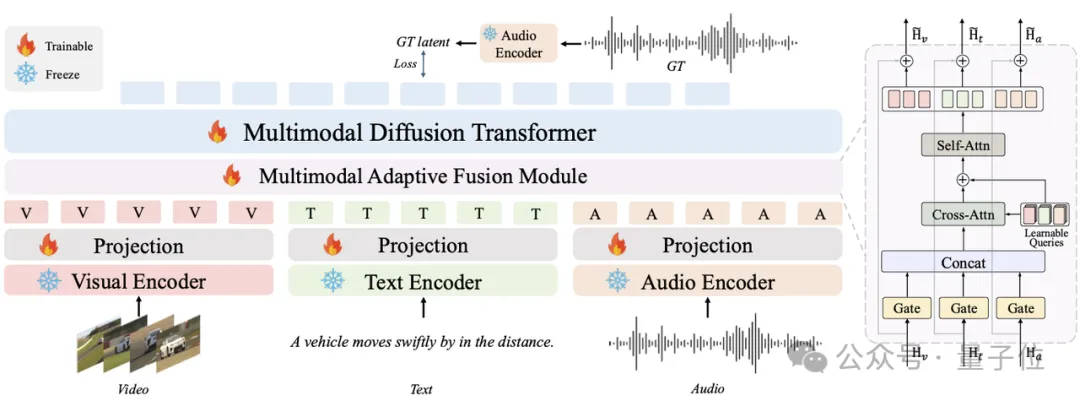
1. 原生多模态骨干打底
全面采用原生适合多模态融合的
Multimodal Diffusion Transformer (MMDiT)
作为模型骨架,配合MAF模块从零训练了2.7B参数,确保了极高的音画同频与跨模态控制力。
2. Turbo蒸馏加速
基于Flow Matching框架,引入
分布匹配蒸馏(DMD)
将模型蒸馏至4步,同时应用CFG蒸馏去掉了CFG引入的额外NFE开销。
“简单说,就像把一幅需要涂100遍才能完成的画,提炼成只涂4遍的模板——AudioX-Turbo用蒸馏技术把这个‘模板’提炼出来了。”
△图2. 分布匹配对抗蒸馏
结果惊人,AudioX-Turbo仅需
就逼近Teacher模型100步的音质,再得益于扩散判别器,学生模型输出和真实样本的对抗训练,使少步模型在部分性能指标上反超了100步教师模型。
单张RTX 4090上,生成10秒音频仅需
(RTF仅0.02),打开了实时音频生成的想象空间。
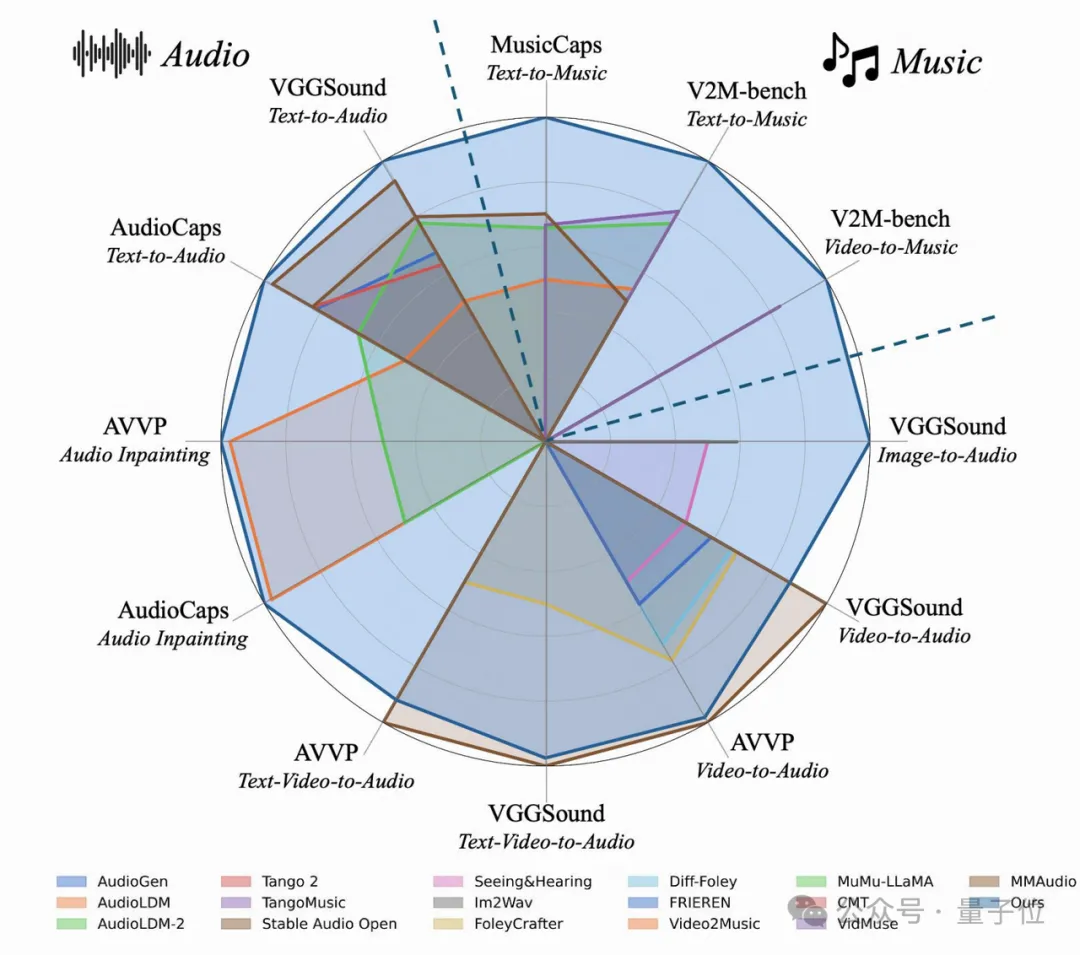
△图3. Audiox-Turbo对比其它模型的全面评测
核心突破二:数据大换血,920万样本让模型“听懂人话”
之前很多音频模型无法精确控制,根源在于数据里的文本标签太“糊”(比如只有简单的环境音概括)。
为此,Noiz AI与港科大团队专门打造了超大规模的多模态音频数据集