

< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
7B打败o3、GPT-5!医学AI智能体让模型学会“看哪里、怎么看”
医学AI Agent到了关键拐点
上海创智学院 LeapQuest 团队 投稿
量子位 | 公众号 QbitAI
医学AI会写解释,但不代表它真的“看到”了关键证据。
过去的医学多模态模型,大多是把一张影像或一段视频编码成视觉特征,然后让大模型生成答案与解释。
但问题在于——一个微小病灶、一个边界变化、一段几秒钟的手术动作,往往就决定了答案是否成立。
而模型“被动接收”视觉上下文时,很容易看错区域、漏看病灶。
上海创智学院LeapQuest团队
浙江大学、上海交通大学、复旦大学
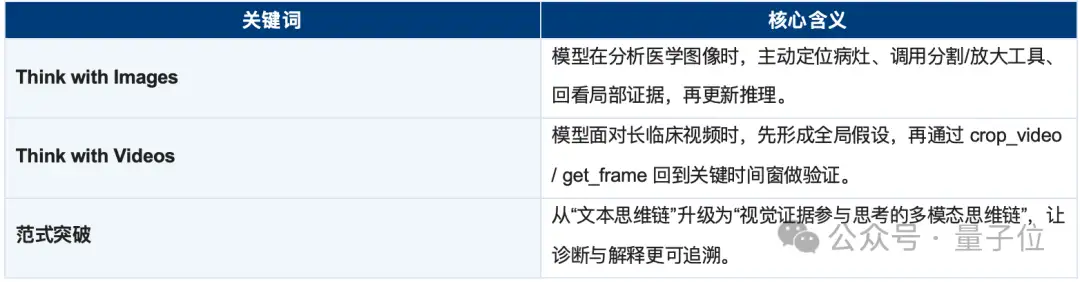
Think with Images/Think with Videos
范式应用在医学AI领域:
模型不再只是看完图像或视频后生成解释,而是在推理链中主动调用视觉工具,重新观察关键区域或关键时刻,并用新证据修正判断。
这意味着,视觉不再只是输入,视觉证据本身成了模型思考过程的一部分。
两篇工作的核心关键词如下:
两篇工作不是孤立模型升级,而是共同提出医学AI的新范式:
让视觉证据进入模型的中间思考过程,把“解释”从事后语言生成推进为推理过程中的证据查证。
Ophiuchus:面向医学图像的tool-augmented Think with Images
MedScope:面向临床长视频的Think with Videos
不是更会“写解释”,而是开始会“用视觉证据思考”
医学AI过去最常见的工作方式,是把一张影像或一段视频编码成视觉特征,然后让大模型生成答案与解释。
解释看起来完整,并不代表模型真的看到了关键证据
。尤其在医学场景里,一个微小病灶、一个边界变化、一段几秒钟的手术动作,往往就决定了答案是否成立。
Ophiuchus和MedScope共同把这个问题向前推进了一步:多模态模型不再只是“被动接收视觉上下文”,而是在推理过程中
主动决定是否需要更多证据
,并把工具返回的观察结果纳入后续推理。
这就是医学AI领域首次被系统化提出的 “think with images/think with videos” 范式:视觉不再只是输入,视觉证据本身成为模型思考过程的一部分。
Think with Images
Think with Images:让模型在图像诊断中“重新看一眼”
Ophiuchus的切入点非常直接:现有医学多模态大模型虽然能写出逐步推理,但遇到需要细粒度视觉证据的任务时,仍然容易“
看错区域、漏看病灶、误把正常结构当异常
这不是单纯语言能力不足,而是
因此,Ophiuchus将大模型改造成一个能与医学图像工具协同的视觉智能体。
它可以根据当前推理状态,决定是否调用外部视觉工具:用
BiomedParse
根据文字提示定位医学结构,用
工具调用后的输出不是孤立结果,而会以
observation
的形式回到推理链,驱动下一步判断。