
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
BrowserBC:克隆人类点击,让一次网页操作转化为所有Agent的能力
人类一次录制,Agent就能模拟
量子位 | 公众号 QbitAI
Agent从来不是不会用浏览器,只是浪费太多时间在探索——BrowserBC把人类轨迹蒸馏成可复用Skill来完成Behavior Cloning,用户点一遍,Agent照着就能跑通。
今天的Web Agent,已经不缺「会操作」这件事。
Claude、Codex这类Agent能看页面、能识别按钮和输入框,能点击、输入、跳转、提交。
真正卡住它们的,是另一个问题:
每接一个新任务、每换一个新网站,几乎都要让最强、也最贵的那个模型,从零开始再把整个流程摸索一遍
而这种「从零摸索」,常常摸着摸着就出岔子:
,在几个页面之间反复横跳;慢慢
,越走越远;在搜索结果里来回切换却始终没读全;或者明明已经很接近答案,却提前收手、草草交差。
在摸索一遍之后呢?就算这次侥幸做成了,这点经验也往往随着这一轮对话一起蒸发。下一次同类任务,再换一个Agent,还要从头试错、再踩一遍同样的坑。
于是,一个很朴素的问题浮出水面:
能不能做一次、复用很多次?
更具体一点——能不能让人把任务认真做一遍,把这一遍操作里的「门道」打包下来,然后交给一个更便宜、更小的模型,让它照着做,就能完成同一类任务?
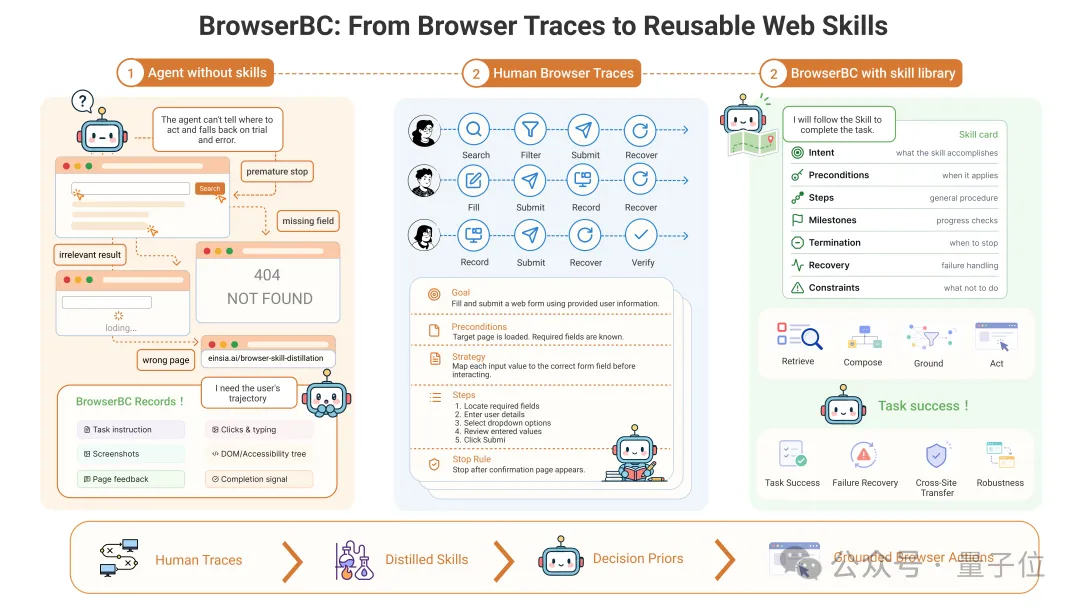
Einsia AI旗下Navers Lab发布的开源项目BrowserBC给出的答案,是一条三步范式:录制→转写成Skill→交付执行
:在浏览器里做任务的时候,把全过程完整记录下来——任务指令、每一步的页面观察(既有渲染出来的截图,也有结构化的DOM/可访问性树快照)、用户的每一个动作(点击、输入、跳转、提交,并带着对应的元素定位)、页面给出的反馈(页面跳转、校验与报错信息、完成信号),以及任务最终落到哪个状态。
:关键在于,它不是把这段操作存成一段「回放脚本」,而是由模型把它转写成一份自然语言的Skill——一份说明书式的「技能卡」,写清楚这类任务该怎么做、怎么判断做对了。
:再把这份Skill交给任意一个模型去读。它据此在真实页面上自己落地操作,而不是机械复刻某一次的点击坐标。
说得通俗一点,BrowserBC有点像
agentic时代的「按键精灵」
传统的按键精灵,会把人的鼠标点击和键盘敲击录下来再回放——但它录的是写死的坐标和按键,页面一变、布局一动,整段脚本立刻就废了。
BrowserBC录的不是坐标,而是把这一遍操作
转写成一份讲清「该做什么、怎么算做完」的技能
它能被另一个模型读懂,能在变了样的页面上举一反三,也能被不断合并、复用——它是那种会「理解」、能迁移、还能直接交给别人用的按键精灵。
这也揭示出BrowserBC的核心——
技能从哪里来,和技能由谁来执行,可以彻底分开
人在浏览器里把任务做一遍,这一遍操作被转写成技能;之后照着技能把同类任务做下去的,是另一个、哪怕更小、更便宜的模型。技能一旦被转写成自然语言,就能在模型之间自由地传递、复用、组合。
这正是通往「通用网页浏览」的关键步骤:
把人类每天的浏览器行为蒸馏给Agent去做
*BrowserBC把人类的浏览器操作轨迹蒸馏成可复用的自然语言技能,为Agent提供访问陌生网站时的“决策先验”。
Github:https://github.com/Einsia/Browser-BC
Blog:https://lab.einsia.ai/browserbc/
Paper:https://lab.einsia.ai/browserbc/paper
人类一次录制,Agent就能模拟
研究团队录制了一个case:
视频链接:https://mp.weixin.qq.com/s/OFXkRh_keR4HzgTImCGjVg
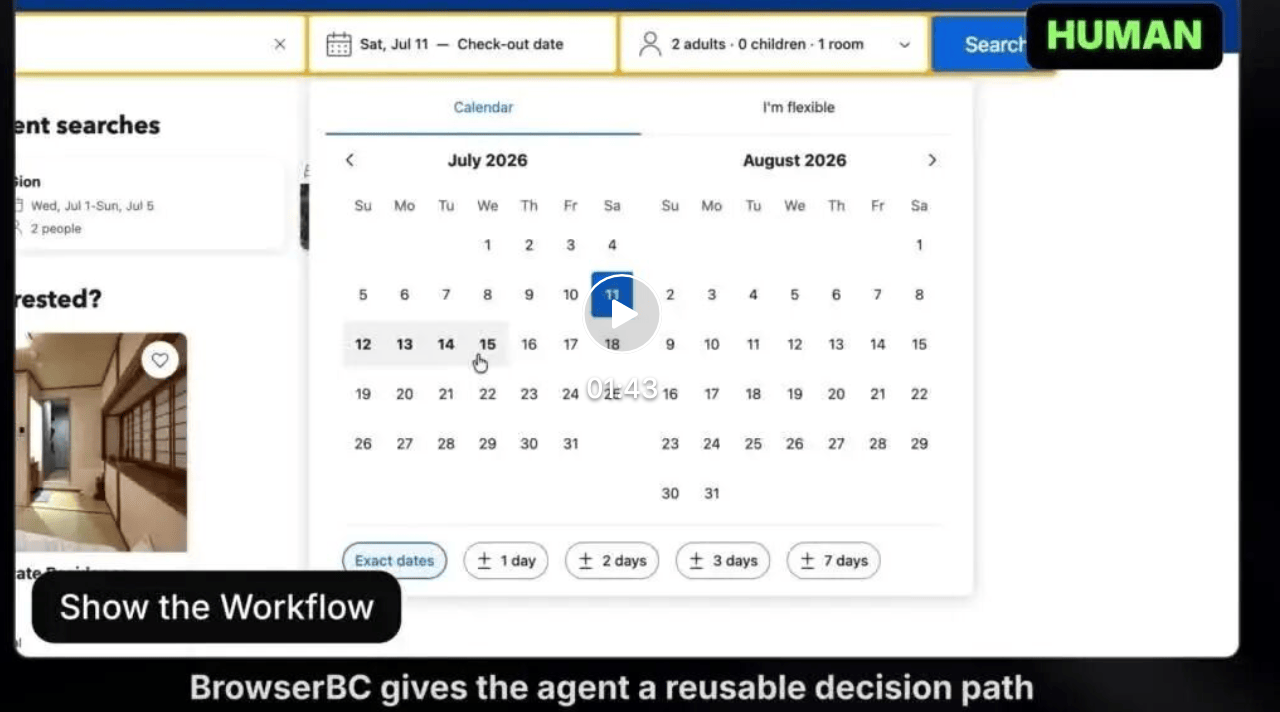
任务很常见:旅行前想要在目的地找一处安心、方便、实惠的民宿,需要在预订网站输入时间、地点、预约人数,按照网站评分、评分数量筛选,并且排序找出里面最优的选项。
这类任务看起来不难,但是小模型经常栽在它上面——不是不理解任务,而是要么不知道怎么用筛选功能,要么产生幻觉输出虚构信息假装完成。
。研究团队先让一个人把它完整做一遍:进入网站→输入时间地点人数→应用合适的筛选器→阅读所有搜索结果→找到最佳选项。整个过程被原样记录下来。
第二步,转写成Skill
。系统把这段操作转写成一张技能卡,而不是一段坐标回放。卡片上写的是这一类任务的通用门道:
:在预订网站找到最佳的住宿选项;
:先写基本信息,搜索之后逐项应用筛选器——这正是小模型最容易不理解或者做不到的地方;
:最后输出可以人工核查的版本;
:官方筛选器可能和用户实际需要的标准不一样,如有需要则需要自己编写脚本筛选。
第三步,交付给一个小模型执行
。这张卡片被交给一个明显更小的模型,让它去完成另外一次旅程的信息检索,做同类型的任务。
没有这张卡片时,它要么跌跌撞撞卡死或者很久才勉强完成任务,要么直接输出幻觉;拿到卡片后,它立刻知道要输入什么信息,要核查什么界面,哪些要依赖网站官方哪些要自己判别——于是稳定地把任务做完了。