< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
CVPR 2026最热方向,被一家杭州团队率先跑进了端侧!
VLM- R1之后再次出手!全球首个端侧流式多模态来了!
henry 发自 凹非寺
量子位 | 公众号 QbitAI
这CVPR也就刚过去没几天,会上还在热议的方向,就已经给一家杭州团队跑进了端侧!
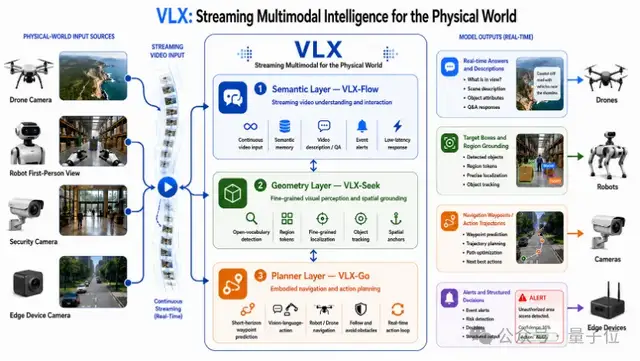
发布全球首个面向物理世界的
端侧流式多模态模型系列
VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:
VLX-Flow:实时流式感知,让视频像水流一样持续输入,模型实时看、实时想、实时更新世界状态。
VLX-Seek:精准定位,从看见走向看清,快速锁定目标。
VLX-Go:行动决策,把感知和定位的结果转化成真实动作——该往哪走、怎么操作,一气呵成。
这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。
与此同时,其原生端侧设计也让它能够真正跑进手机、无人机、机器人这些端侧设备。
而这,也并不是Om AI第一次在VL(视觉语言)领域发力。
去年,他们推出了全网爆火的
作为全球首个将DeepSeek R1强化学习范式引入视觉语言模型的开源项目,上线12小时获得超过2000颗GitHub Star。
48小时登顶GitHub全球趋势榜,至今已斩获6000+Star。
这一次,他们交出的新答卷,是VLX。
一条通往物理世界的能力链
为了更好地理解VLX这次的技术路线,我们可以把它拆成两个关键词:
所谓流式多模态,就是让AI能够在物理世界中持续、实时地感知环境,并最终形成一条完整的能力链:
感知(Perception)→ 精准定位(Grounding)→ 行动(Action)。
它跟我们此前在语音助手里“听”到的流式多模态不同。
语音助手强调的是人与AI的实时交互,而VLX关注的,则是AI在物理世界中持续观察、持续判断,并最终驱动行动,完成从“看图”到“做事”的跨越。
这种定位的不同,其实反映的是VLM角色的转变。
等领域快速发展,VLM已经不再只是LLM的一个能力模块,而是在逐渐成为空间理解、视频理解乃至动作规划的新一代基础设施。
VLM不仅需要看图说话,更需要具备持续感知、精准定位和驱动行动的能力,从而为下游任务提供统一、精准的基座能力。
一个很直观的信号来自今年CVPR。
数据显示,VLM/多模态相关论文占比已经从去年的4.9%增长到10.6%,几乎翻倍,成为近年来增长最快的研究方向之一。
而在论文数量快速增长的背后,最值得关注的两个关键词,就是
实时感知(Streaming)
定位(Grounding)
(注:Grounding的核心就是让模型根据一句自然语言描述,准确找到图像或视频中对应的对象、区域和概念)
VLX的整套设计,也正是围绕这两个方向展开,并进一步把能力延伸到了最终的行动。
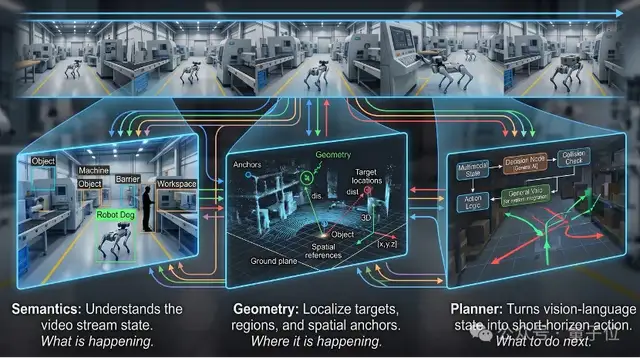
VLX-Flow:流式推理
首先是VLX-Flow,负责持续感知,解决的是看见。
在真实世界中,由于物体始终处于运动之中,环境、状态不断变化、视角切换也时刻发生。
一次性的观察,很难应对这样
的环境。因此,模型必须像人一样不断接收新信息、持续更新对环境的理解。
传统视频模型往往将整段视频切成帧,一次性送入模型做离线理解。
视频一长,不仅计算成本急剧上升,还容易丢失前文信息,难以支撑实时交互。
为解决这一问题,Flow采用了流式处理。
让画面像水流一样持续涌入,靠增量编码和缓存机制不断更新自己的视觉状态,既不用反复重算历史,也不会因为视频变长而失忆。
技术层面, Flow用Linear Attention替代标准Attention,并结合双层记忆机制,让视频流能够持续进入模型而不会因上下文增长导致显存爆炸。
也就是说,它不等视频播完再理解,而是一边看一边更新对环境的认知,必要时还能主动发起交互,并做到实时视频流下的低延迟响应。
不过,持续看只是第一步,模型还必须知道
VLX-Seek:精细感知
,负责精细感知,解决的是看得准。
以机器人为例,仅仅知道“前面有一把椅子”远远不够,它还需要准确知道目标