
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
OceanBase湖库一体,重新定义AI数据库
一套技术栈实现离在线统一
OceanBase CTO 杨传辉
量子位 | 公众号 QbitAI
AI时代苟日新,日日新,又日新,
主流数据库的发展经历了几次重要演进:从最早的OLTP数据库,到OLAP从其中分离出来成为数据仓库,再到大数据系统。长期以来,数据库架构主要围绕人类应用、确定性交易和结构化数据分析设计。
今天,新的变化正在发生。
AI Agent不再只是读取数据、回答问题,而是开始调用工具、生成代码、执行任务、修改状态,甚至参与业务流程。数据库的使用者,正在从人类应用扩展到大量自主运行的
这带来一个根本问题:当成千上万个Agent同时读写、搜索、试错、回滚和生成上下文,数据库还应该是过去的样子吗?
我认为,答案是否定的。
首先AI正在同时改变三件事:
数据库的使用者,从应用扩展到Agent;
数据库管理的数据,从结构化数据扩展到涵盖结构化、半结构化与非结构化的多模态数据;
数据库承载的工作负载,从事务和分析扩展到搜索、上下文工程与AI应用。
因此,AI数据库不是传统数据库增加几个AI函数,也不是向量数据库补上SQL能力。它要解决的是AI进入生产系统后的数据基础设施问题。
多模态数据需要在统一底座上被管理,在线服务和离线计算需要融合,Agent需要获得实时、可信、连续的上下文,读写、试错、回滚和治理中保持数据库级一致性与可靠性。
这不是一次功能增强,而是在AI时代
重新定义数据库的技术架构
AI时代,数据库走向一体化
我们先看行业发生了什么。
Databricks和Snowflake从湖仓和数仓系统出发,不断补充OLTP的事务能力;OceanBase和Oracle从交易库出发,持续提升OLAP和大数据能力;MongoDB、Milvus、Elasticsearch从专用库出发,连续增强通用数据库的能力。
不管出发点如何,不同路线都正在向一个能够同时处理交易、分析、搜索、向量以及AI计算的统一数据底座演进。
其中OceanBase一直坚持走
最早我们开始做分布式OLTP,解决了在线交易的扩展性和可靠性。后来我们又在OLTP基础上加入了实时OLAP支持,消除了TP到AP的数据搬运。去年,我们发布了多模一体化,把向量、全文、JSON、GIS等能力带进同一个数据库引擎。
直到今天,我们正式发布
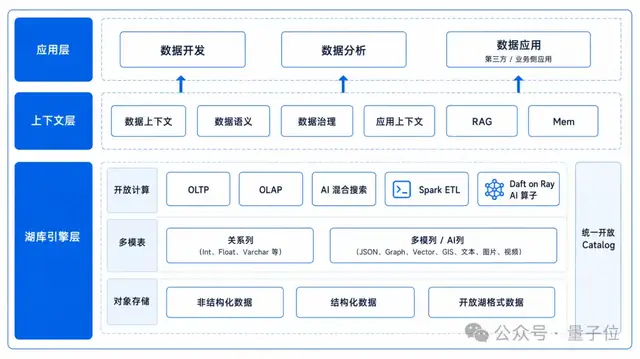
OceanBase湖库一体的AI数据库
,是沿着这条路继续往前走:把库里的实时事务能力、湖上的开放存储和开放计算能力,放到
我理解的湖库一体(OceanBase Lakebase),不单单停留在数据库外接一个数据湖,也不能只是给湖仓补几个在线查询接口。要让它进入生产系统,至少要合并三条边界:
第一,数据形态要统一。
结构化数据、半结构化数据、非结构化数据、向量、图、全文索引,不能分散在不同系统里各管一份。它们应该在同一套表语义下被管理。
第二,计算路径要统一。
SQL查询、实时分析、混合搜索、Spark ETL、Ray上的AI计算,应该围绕同一份数据工作,而不是靠不断导出、转换、中间落盘来协作。
第三,治理边界要统一。
元数据、权限、行级控制、审计、版本、生命周期,必须对所有数据类型一致生效。否则结构化字段有权限控制,向量检索却绕过了权限,这样的系统进不了企业生产。
这也是OceanBase Lakebase的设计出发点:
底层使用存算分离的设计架构。
数据存在对象存储上,计算层独立运行。AI Agent的工作负载本质上是突发式的——每一个Agent都可能在任何一天流量激增,每一天都可能有一个小型的双十一。存算分离让计算层能够独立伸缩,负载上来瞬间扩容,空闲时缩到零。
统一结构化、半结构化、非结构化数据以及多模态数据。
除了原有的SQL计算(OLTP、OLAP、AI搜索),也支持Spark处理ETL、Daft on Ray处理AI加工。把这些计算引擎统一在同一份数据之上,是湖库一体区别于传统数据库的核心设计目标。
湖的价值在开放、弹性和成本。库的价值在事务、一致性、低延迟和治理。AI时代需要把这两组能力合在一起。
此外还有一个关键价值容易被忽视——
传统做法里,数据加工是离线的,加工完的结果还要搬回在线系统才能服务应用,中间有T+1甚至更长的延迟。
湖库一体直接把离线加工和在线服务统一在同一份数据上:Spark ETL的产出,SQL引擎立即可查;模型推理生成的向量,混合搜索立即可用。不再有“加工完了还要等同步”的窗口期。
这里实时性不是靠加速搬运实现的,而是靠
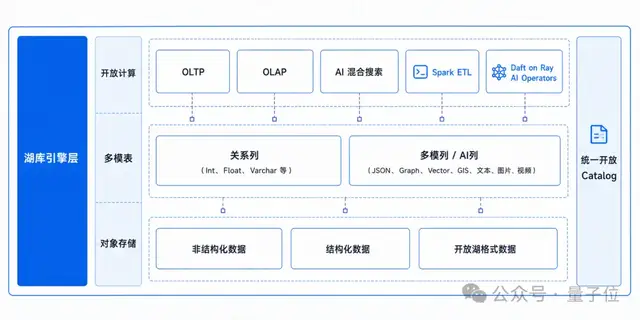
多模表:AI数据库的核心数据结构
OceanBase的第二个关键点在
原来的关系数据库,底层是一张关系表——里面有Int、Float、Varchar,所有列都是结构化数据。
今天的AI数据库,底层应该是一张多模表。
多模表既包括原有结构化数据的关系列,也包括非结构化数据的多模列与AI列。非结构化数据,可以在外部Embedding或者打标之后以向量或者文本的方式写入到多模表,也可以直接以LOB的形式写入到多模表。