
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
困住医疗AI的死循环,终于有国产玩家跑通了
在多项关键医疗测评上打败了GPT-5.5
「智能是平等的,但是context是不平等的。」
Sam Altman不久前说了一句话,大意是:智能终将像水电一样成为基础设施,人人都能调用。但他也指出,AI当前最大的瓶颈不在智能,在
context gap
——系统没法持续理解用户的真实场景。
a16z在今年3月的一篇分析里说得更直接:没有正确context的AI Agent,基本无用。
这两个判断叠在一起,恰好解答了一个困扰我很久的疑惑:
为什么有些很火的垂直赛道,迟迟未能形成马太效应?比如医疗
AI发展到现在,通用大模型的格局已经很清楚了。头部三五家吃下绝大多数市场,后来者连牌桌都很难上。
强者恒强,几乎是常识。
但医疗偏偏是个例外。这条赛道热了好几年,上百家公司涌进来,论文一茬接一茬,评测榜单你追我赶。
可奇怪的是,似乎没有人真正拉开明显差距。为什么?
如果从context的角度进行思考,答案很可能是:
不是大家实力接近,恰恰相反,是因为整个行业卡在了同一个结构性死结里——
数据、模型、场景,三者的闭环断了
数据在医疗行业的角色有点像「萧何」,成也它,败也它。
看起来数据足够丰富,病历、影像、检验结果几乎无处不在,所以早期大家一窝蜂涌进来。
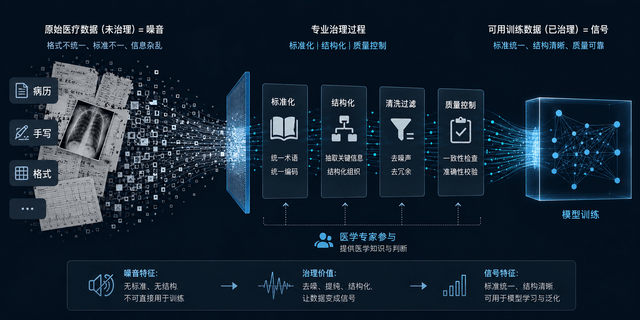
但真正进来之后才发现:数据确实不缺了,但没法直接用啊。
很多厂商手里的确有大量原始医疗数据,
但由于缺乏专业的标准化治理能力
,所以难以转化为有效训练素材。
说白了,专业的事交给专业的人。医疗数据的标准化处理,需要懂医学的人来干。
像DeepMind这样的顶级实验室还能自搭内部医学团队,但对大多数公司来说,他们往往只能依赖外部医学标注团队或医院合作方,通过「外包」来补齐能力缺口。
走外包当然没问题,问题是高质量的医学治理资源本身就是稀缺品,而且很难规模化复制。
通俗点,能接这种活的团队就那么多,排队都排不过来。
原始数据看起来很多,但真正经过专业治理、能稳定喂进训练流程的,其实非常有限
说到底,原始数据不等于context。没经过治理的数据,是噪音,不是信号。
很多人的想法是,虽然高质量数据少了点,但只要把模型扔进真实环境跑起来,不就能持续获取新数据、形成数据飞轮了吗?
思路没错,但飞轮恰恰卡在了这一步。
绝大多数医疗AI产品仍停留在「问答助手」阶段,能回答问题,却无法深度嵌入医生的工作流。
一个问答机器人哪怕每天被问一万次,沉淀下来的也只是「用户问了什么、AI怎么答的」,而真正有价值的数据,来自诊疗过程本身——
医生如何诊断、如何开药、如何调整治疗方案,以及患者最终恢复得怎么样。
进不去这些核心环节,就拿不到有效增量数据。
拿不到有效增量数据,模型当然还能靠公开文献和语料继续「刷分」,但这种提升更多停留在知识层面,而非临床决策与工作流层面。
结果就是一个很矛盾的现象:
评测很强,但医院里的实际使用频率并不高
产品进不了临床→拿不到真实诊疗数据→模型迭代没有燃料→产品更进不去
而现实的发展轨迹,几乎就是这个循环的真实写照。