< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
从看懂世界到做对动作,卧安机器人OneModel 1.7用一条「隐式通路」打通了具身智能的关键断层
在潜在空间中完成信息传导
具身智能行业悬而未决的一个核心问题,有了一种新的回答。
World Model「看懂了」环境变化,动作策略却依然「做不对」——这个从理解到执行的传导断层,是当前制约家庭机器人走出实验室的关键瓶颈之一。
5 月 20 日,卧安机器人(OneRobotics,6600.HK)正式发布自研世界动作模型OneModel 1.7 FrontoStria-RL,给出了一套系统性的解决方案:用一条名为 Predictive Policy Latent的隐式传导通路,把世界模型对场景的理解直接「灌」进动作执行模块——不靠显式的中间图像或坐标传递,而是在潜在空间中完成信息传导。在此之前,支撑这一架构的两篇核心论文已于 5 月 12 日在 arxiv 公开。
实测成绩相当能打。在具身智能标准评测基准 LIBERO 上,OneModel 1.7 平均成功率达到 99%,领先 π0.5、GR00T-N1.5、OpenVLA-OFT 等主流公开模型;真机部署中,日常操作任务成功率 99%,高精度任务成功率 97%。
这家由哈工大 90 后校友李志晨创立、「中国机器人教父」李泽湘教授与微电子专家高秉强教授同时担任董事的公司,2025 年底以约 18 亿港元募资规模登陆港交所,是具身智能领域截至目前 IPO 融资规模最大的公司。但这篇文章关注的不是它的商业化成绩,而是它刚刚发布的模型架构。
差不多同一时间,高盛于 5 月 26 日发布了中国人形机器人中期盘点报告(Mid-year check-in: Several steps closer toward commercial reality),披露了其对中国 14 家头部机器人企业的调研情况。但值得注意的是,这 14 家涵盖了硬件、传感器、自动化等不同环节的公司,其中被高盛明确点名为「正在推进 VLA + World Model 融合方向」的只有 4 家,卧安机器人是其中唯一的上市公司——One Robotics(卧安机器人,6600.HK)、Galaxea(星海图)、Galbot(银河通用)和 Spirit AI(千寻智能)。报告在卧安机器人的调研介绍中,直接提及了 OneModel 1.7 的 latent world action model 架构,以及 motion-centric control 和 success memory 等核心模块。
高盛在报告中指出,行业讨论正在从单一 VLA 框架,快速转向 VLA / VTLA 与 World Model 融合的多模态执行栈,而高质量真实世界数据仍然是制约实际部署的首要瓶颈——这两个判断与卧安 OneModel 1.7 的技术方向和数据布局高度吻合。
这件事为什么值得拆解?因为它回应的不是「模型参数要不要更大」的问题,而是一个更根本的架构问题:World Model 和动作模型之间,到底该怎么接?
NVIDIA 澳门站:从仿真到客厅
故事的一个具体切面,发生在 NVIDIA 创业企业展示澳门站。
2026 年 5 月,卧安机器人《From Isaac Lab to Your Living Room》为主题亮相。这个主题本身就传递了一个信号:卧安关注的不只是仿真环境里的训练效果,而是从仿真训练到模型迭代再到端侧部署的全链路闭环——最终目标是让机器人真正在你家客厅里干活。
展示中,搭载 OneModel 1.7 的卧安保姆机器人 onero H1 在模拟家庭场景中完成了洗衣全流程:自主识别散落衣物,规划路径避障,抓取柔性衣物,打开洗衣机门,分类投放,关闭舱门。根据现场演示,全程无遥操作介入。
搭载 OneModel 1.7 的 onero H1 在模拟家庭场景中完成洗衣全流程,全程自主决策、无遥操作
但这次展示的看点不在于「又一个机器人洗衣服的 demo」。把它放到 NVIDIA Physical AI 和 Isaac Lab / Isaac Sim 仿真工具链的大背景中看,更值得关注的是卧安机器人(OneRobotics)的技术路线选择:它没有走单一 VLA 端到端映射的路线,而是构建了一套将 World Model 与动作执行模型通过隐式传导机制连接起来的架构—RL-Latent World Action Model(RL-LWAM)。
据了解,在具身智能创业公司中,卧安机器人是最早提出并落地「通过隐式传导架构连接世界模型与动作模型」这一技术方向的公司。当行业大部分团队还在围绕单一 VLA 或单独的 World Model 做文章时,卧安选择把两者用一条隐式通路接起来——这个判断现在看来踩到了行业演进的方向上。
拆解 OneModel 1.7:一条从理解到执行的隐式通路
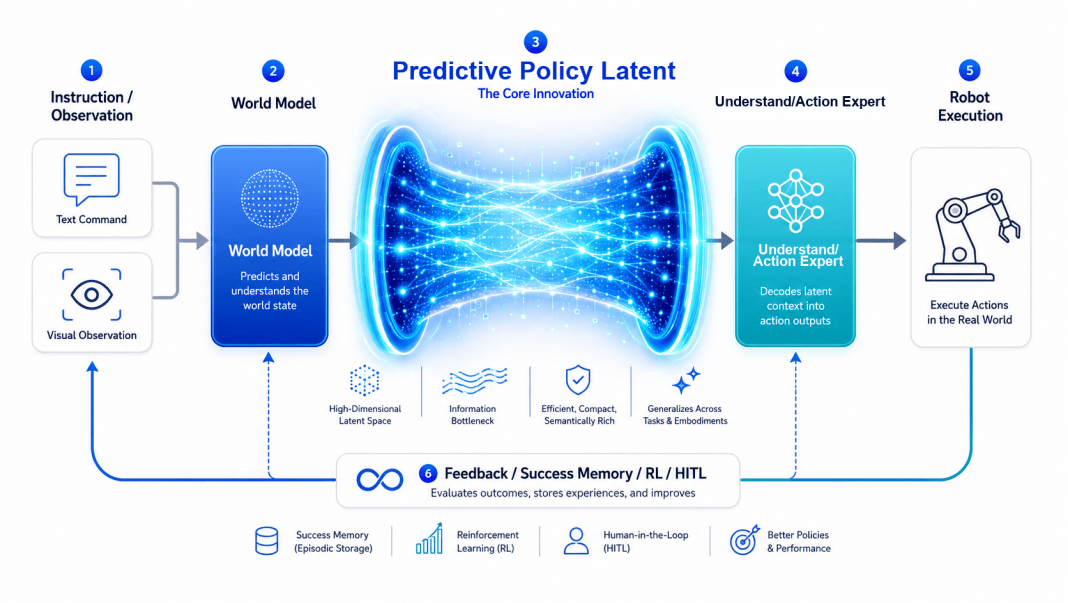
OneModel 1.7 FrontoStria-RL 的 RL-LWAM 架构,拆开来看其实在回答一个核心问题:怎么让世界模型对环境的理解,真正传导到机器人的动作执行上?
RL-LWAM 架构由三大核心模块组成,彼此通过一个关键的隐式传导机制——Predictive Policy Latent——连通,而非依赖显式的中间图像或坐标传递。
OneModel 1.7 FrontoStria-RL 完整架构。Predictive Policy Latent 作为核心传导机制,连接 World Model、Understand Expert 与 Action Expert。
World Model:跨场景泛化的基础
World Model 模块负责对环境状态和任务演化建立预测能力,包括物体关系、空间结构和动态变化趋势的理解。在家庭场景中,这意味着机器人需要理解「碗架从左边挪到了右边」「橱柜门角度变了」这类人类觉得不值一提、但对机器人而言是全新场景的变化。
World Model 不直接输出动作指令,它输出的是对当前场景和任务状态的结构化理解。关键问题是:这些理解怎么变成机器人能执行的动作?
Predictive Policy Latent:连接理解与执行的关键传导机制
这是 OneModel 1.7 架构中最值得关注的设计。Predictive Policy Latent 不是一个独立模块,而是一个隐式传导机制——它把 World Model 对场景、物体、空间关系和动作后果的理解,压缩转化为一组潜在空间中的策略表征,再传递给下游的 Understand Expert 和 Action Expert。
为什么用「隐式」而非「显式」?在传统管线式架构中,World Model 的输出往往是显式的中间表示,比如预测的下一帧图像、关键点坐标或语义标签。这些显式信号在传递过程中会丢失信息、引入生成幻觉和推理延迟,在开放家庭环境中尤其脆弱。Predictive Policy Latent 的做法不同:训练时用「未来信息」来教会模型什么是好的动作决策方向,部署时则只靠当前观测就能做出等效判断——信息密度更高,推理更快,且不引入生成式噪声。
这条隐式通路的价值,最终体现在端到端的真机部署结果中:OneModel 1.7 在日常操作任务(洗衣、叠衣、洗碗机操作等)上达到约 99% 的平均成功率,在拔插试管、倒咖啡豆等高精度任务上达到约 97%。这些任务涵盖了从柔性物体操作到极小容错空间的精细操作——从结果来看,World Model 的场景理解经过 PPL 隐式传导后,确实在驱动下游的任务分解和动作执行上发挥了作用。
Understand Expert + Skill 体系:任务理解与技能调度
Understand Expert 模块处于 World Model 和 Action Expert 之间,负责将世界模型提供的场景理解与具体的任务指令对接,进行 Skill 调度。面对「把衣服放进洗衣机」这样一个看似简单的指令,Understand Expert 需要分解出一系列子技能:定位衣物、判断抓取策略(柔性物体需要区别于刚性物体的抓取方式)、规划移动路径、识别洗衣机状态、执行投放动作。
Skill 体系的价值在于复用。一旦某个子技能(比如「打开带手柄的门」)被模型习得,它可以在不同任务和不同场景中被调度复用,而不需要为每个新任务从头训练。
Action Expert + MCF-Proto:精准执行的底层引擎
Action Expert 负责最终的动作输出。其中一个关键组件是 MCF-Proto,全称 Motion-Centric Action Frame。当前主流 VLA 模型的 action head 几乎都是在固定世界坐标系下直接预测位移,这种方式对相机视角变化和机器人初始位姿偏差非常敏感。MCF-Proto 的做法不同:它围绕任务相关的局部运动结构(比如门铰链、导轨、折叠线)组织动作原型,再映射回实际机器人动作,从表征结构层面降低几何扰动带来的分布偏移。
LIBERO-plus 扰动测试直接验证了这一设计的效果。在七类扰动条件下,MCF-Proto 在六类中取得最优结果。其中最具实际意义的两类是 Camera(相机视角变化)和 Robot(机器人初始位姿偏差),MCF-Proto 分别达到 69.7% 和 66.0%,领先最强基线 3.3 和 15.7 个百分点。这两类恰恰是家庭环境中最常见的变化——你每天把机器人放在客厅的起始位置都不会完全一致,摄像头角度也会有微小偏差。
LIBERO-plus 七类扰动鲁棒性对比
RL 闭环 + Success Memory:持续进化的机制
RL-LWAM 架构中的「RL」不只是指训练阶段使用强化学习,更指向一套部署后持续进化的闭环机制。
强化学习闭环将真实部署中的反馈持续回流至模型。而 Success Memory 机制则进一步筛选和存储成功执行的经验轨迹,配合 Retrieve-then-Steer 策略,在面对新任务或新场景时,模型可以先检索最相关的成功记忆,再据此调整当前的动作策略。SimplerEnv 仿真测试验证的是 Retrieve-then-Steer 机制的增益——该机制将 CogACT 的平均成功率从 75.8% 提升至 79.5%,提升 3.7 个百分点,说明 Success Memory 确实能在不更新模型参数的情况下带来可观的适应性增益。
SimplerEnv 平均成功率对比