

< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
清华系团队给大模型织了一张“智能算力电网”
单位Token成本降低40%
量子位 | 公众号 QbitAI
AI芯片,正在机房里猛猛吃灰。
海外高端GPU供不应求、又贵又难买;
国产芯片产能好不容易上来了,结果是「能用但不好用」,生态不全、适配难、推理优化门槛高,大量国产卡就这么空转着,电费照烧,却产不出一颗能用的Token。
企业想用AI,偏偏卡在了最不该卡的环节,
所有人都在比谁的模型参数更大,但真正决定AI能不能落地的,其实是另一件没那么性感的事:
一颗Token,能不能被稳定、便宜、规模化地生产出来。
死磕这件事的,是一支从中国超级计算体系里走出来的年轻团队,
这家公司成立于2021年,由技术出身清华,有国家级算力中心工程经验的核心科研团队联合组建,是国内最早将超算智算并行优化的技术进行产业化的团队之一。
名字取自“实事求是,甘为基石”,寄托着创始团队对算力基础设施地位的深刻认知。其创始人兼董事长
,出生于1993年,毕业于清华大学,是清华计算机系博士后。
自主研发的并行优化技术
,将高性能计算(HPC)与人工智能计算深度融合,专治各种
在他们看来,现在的AI行业根本不需要再多一个算力转租平台,要打破国产算力空转的僵局,必须彻底跳出传统租赁的浅层模式。
是石科技给出的解法直击本质:
紧扣“Token标准化、国产化、效率提升”这三件事,直接重构算力变现路径,重磅打造国产TOKEN调优工厂。
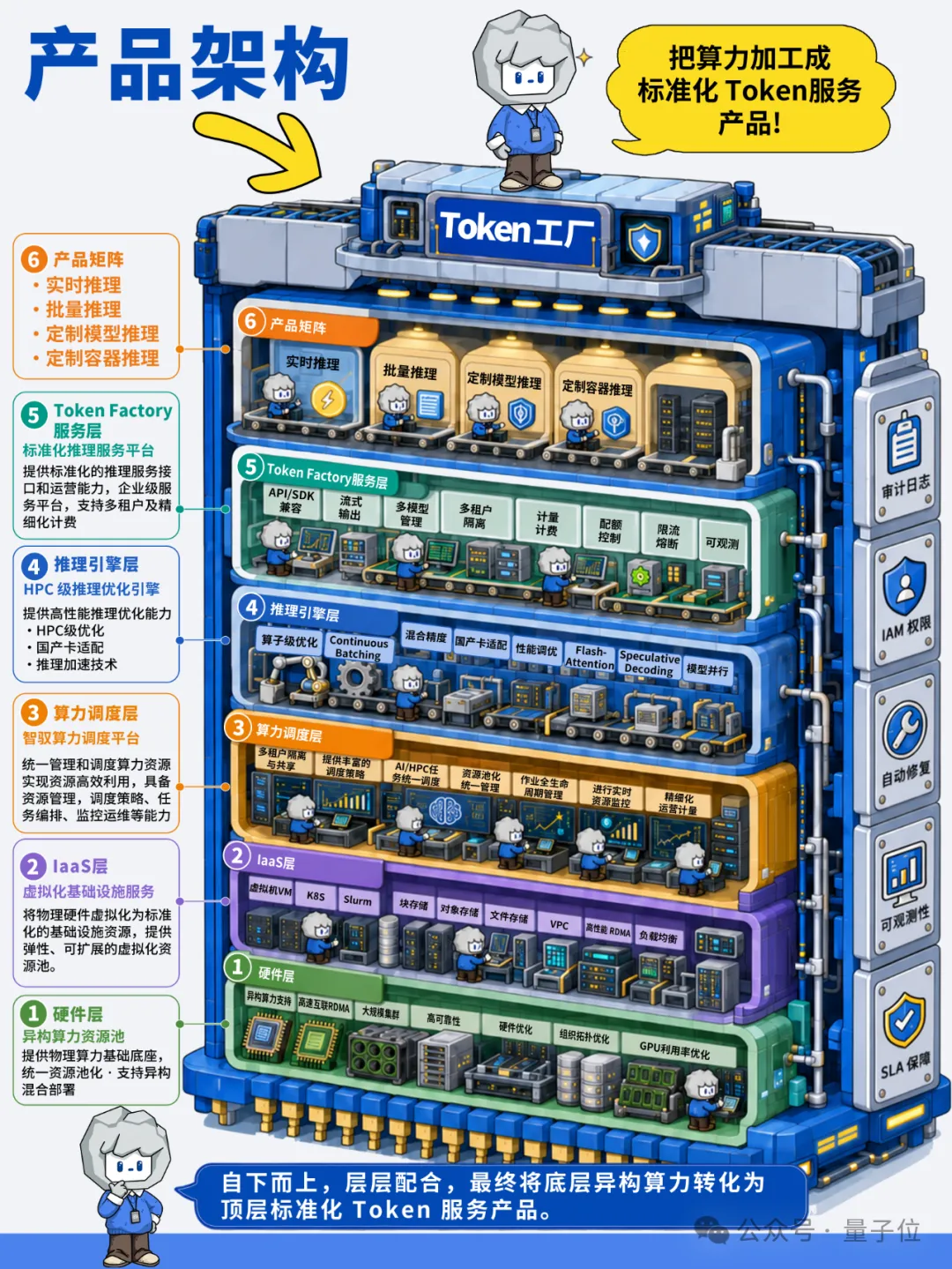
大模型也有了算力“电网”:插上插头,算力秒变Token产能
是石科技TOKEN工厂的第一层技术底座,来自异构算力的全域整合与深度国产化适配。
区别于行业常见的单一算力资源模式,是石科技搭建了全域异构算力资源池,全面兼容NVIDIA GPU、国产AI芯片(包括昇腾、昆仑芯、天数、太初、瀚博半导体等),以及云厂商算力、边缘算力等多源渠道。
通过智能调度与弹性扩缩容技术,实现算力资源的统一纳管、智能分配与动态扩容,让企业不再受困于“算力采购难、资源碎片化”。
打个比方,这就像一张“全域智能电网”。
过去每家工厂只能用自己的发电机(单一算力),买不到柴油就停产,发电机坏了就瘫痪。
是石科技则类似于搭建了一张覆盖全国的算力网络,把各地的风电、水电、火电、太阳能电(各种算力)全部接入统一电网。
企业需要用电时,只需“插上插头”,电网就会自动调度、分配与你需求最匹配的电给你,你完全不用关心电是从哪个具体的电网节点送过来的。
更关键的是,是石科技团队完成了主流国产AI芯片的深度适配与专项优化,打通了
框架适配、算子兼容、通信优化、性能调优全链路
在这张电网的“变电与稳压”作用下,原本闲置、难调通的国产算力,在这里能被高效转化为
稳定、可用、低成本的标准化Token推理产能
通过不断提升算力利用效率,以及充分利用闲时的算力,或者根据客户需求定制专属算力资源,国产Token就可以真正变成可商用的产能优势。
对此,一位长期从事AI基础设施的工程师评价说:
过去我们买了国产卡,总要花几个月去调驱动、改框架、修bug。是石科技把这条路铺好了。国产卡不再是“摆设”,而是真正能跑生产的引擎。
把芯片性能榨干到极限:吞吐暴涨50%,Token成本硬砍40%
如果说算力池化是底座,那么
就是TOKEN工厂的核心技术壁垒。
是石科技团队深耕高性能计算领域多年,在严格恪守企业级SLA服务标准的前提下,从算子、内存、调度、解码等全维度进行技术革新。
CUDA Kernel算子级优化、PagedAttention内存优化、Continuous Batching连续批处理、混合精度推理……这些技术被系统性地部署在TOKEN工厂的生产线上。
配合FlashAttention、推测解码、KV Cache精细化管理、模型并行(TP/PP)等前沿加速方案,GPU等国产芯片的资源利用率大幅提升,Token吞吐总量显著增加,单位Token生产成本大幅下降。