
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
材料版AlphaFold来了!40个工业任务全方位SOTA,AI4S迎来行业大突破
叠加LLM“训练buff”,材料AI终于学会了“物理直觉”
量子位 | 公众号 QbitAI
AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
众所周知,理论计算和真实实验往往存在偏差。如果AI模型一直只在计算生成的完美数据上跑,一到“真场面”必然出问题。
尽管如此,AI4S大部分模型却还是在各种计算理论榜单上卷效果,材料领域也不例外,在Matbench Discovery或Open Catalyst Project上刷成绩的AI模型比比皆是。
其中固然有真实数据稀缺的原因。
但更重要的是,在工业实验数据集上做预测往往更难,相比用固定的输入预测固定的输出,真实实验数据集不仅存在噪声、有误差,数据要求也往往直接取决于特定工业需求。
深度原理Deep Principle
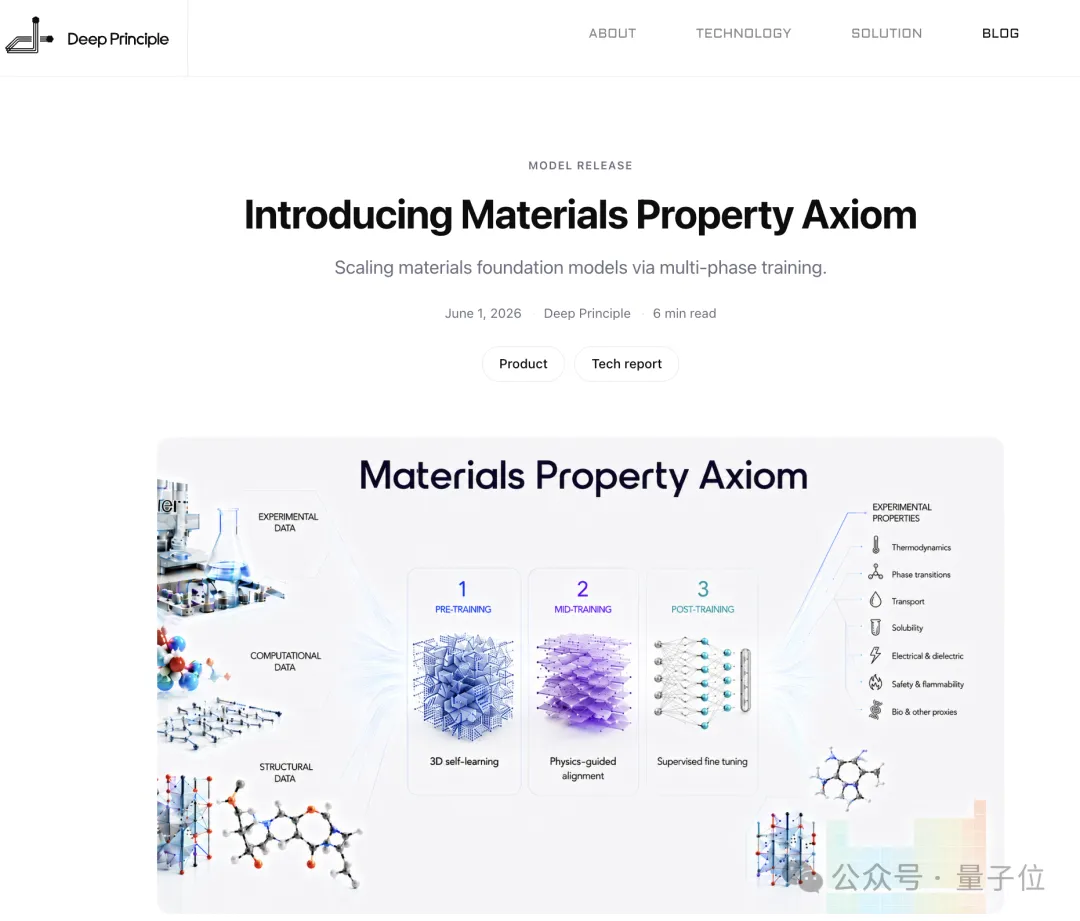
材料基座模型MPA(Materials Property Axiom)
,走了一条截然不同的“野”路子——
把大语言模型的训练方式直接拿来用,一举在
同样是真实数据稀缺的情况,为何MPA如此优秀?
一起来看看模型到底是怎么训练的。
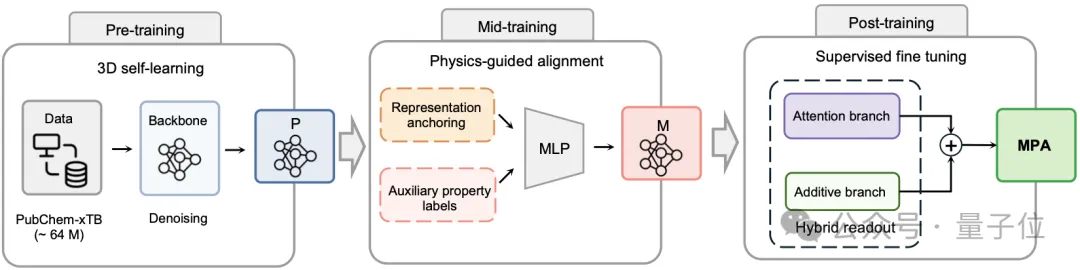
MPA架构本身基于Transformer模型,其结构可以非常直观地分为
“躯干”是材料基座模型通用的图Transformer,用于存储核心的通用知识;
“头”则根据不同训练阶段有所差异,主要是为了让模型适配不同的训练任务。
这次最核心的两大突破,在于
训练模式的改变和后训练阶段“头”的设计
第一点,mid-training的加入。
之前的材料基座模型,训练模式基本分为两个阶段,预训练(pre-training)和直接微调。
其中,预训练是基于通用知识库对模型做一个当前行业的“基础通识训练”,最后通过微调“精细任务优化”。
而在大模型模型(LLM)的实践中,大家早就发现这样的训练模式还不足以“喂饱”它,因此往往要在预训练和后训练中间再叠加一层中期训练(mid-training),用来让模型在中等规模大小的通用任务(如代码调试、数学谜题等)方面取得更好的表现,最终才能在更精细的特定任务上微调取得最佳效果。
为什么要对参数量没那么大的模型也这样做?
事实上,正如通用语料和特定单点任务存在鸿沟一样,材料性质预测模型,同样需要弥补从理论计算直接到实验数据预测之间的鸿沟。
这其中的关键,在于建立AI对于真实材料需求的
从分子结构到“物理直觉”到底差了什么?
如果将各个原子类比为人类的五官,AI模型学习
时,就像是在学习人类五官的位置,特定的分子有特定的五官分布,但整体仍然有规律可循。
以苯环为例,AI在看过一系列苯环架构后,就能理解“六个碳在一个平面上”、或是“C-C键长1.4Å”这样的特征信息。
然而,AI学习不同的分子结构后,却并没有认识到相似结构间隐含的
,就像能识别不同人脸却无法理解共同的表情规律一样。
还是以苯环为例,虽然AI一眼认出来这是苯环,但是对于苯环的生成焓、以及苯环的偶极矩有什么特征一点头绪都没有,更别提总结出“有OH基团的分子偶极矩通常偏大”这样的规律。
这样一来,即使AI在预训练阶段堆的数据再多,实际到数据稀缺的真实场景下表现还是不好。
基于此,MPA特意增加了一层专门针对于“物理对齐”(physics-guided alignment)的训练,来弥补模型从分子结构的理论计算直接到下游实验任务的鸿沟。
这个过程因为模型需要在各种基本物理特性的概念对齐,因此“没有噪声”而且“容易大规模产生”的各种特性的第一性原理计算数据,就成为了首选,深度原理此前积累的大规模计算数据,这次也恰好用在了mid-training上。
第二点,就是针对实验预测任务设计的后训练“头”的创新了。
相比于沿用前中期那套现成的“头”,MPA在后训练阶段专门设计了一种叫Hybrid Readout的“混合头”。
它的核心,是给模型准备了两条路:一条自由的,一条受约束的。