
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
刚刚,全球⾸个“事件级预测”具身智能世界模型来了!
从按帧学动作,到按「事件」理解世界
量子位 | 公众号 QbitAI
让机器人把杯子递过去——
这个看似简单的任务,对当前的具身大模型来说,却是一场逐帧填空的考试:
预测0.1秒后手在哪、0.2秒后手在哪……
把一个完整动作切成几十张几乎雷同的画面,让模型一帧一帧去学。
结果,模型记住的是「手指每帧挪几毫米」,而不是「把杯子抓住」这个目标,换个杯子、换张桌子,节奏稍变,立刻翻车!!
刚刚,自变量机器人团队带来全新解法——
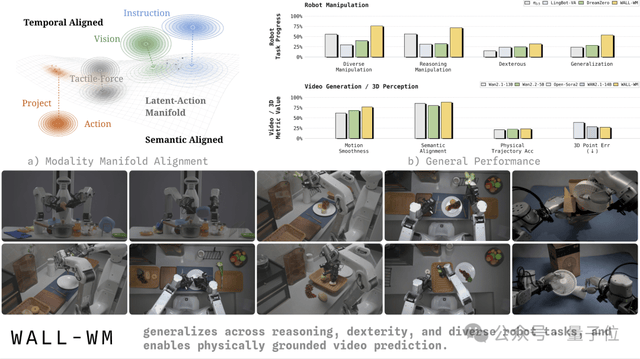
发布全球首个「事件级预测」具身智能世界模型WALL-WM。
WALL-WM把世界模型的预测单位从时间帧换成了
模型不再问0.1秒后是什么样,而是直接想象抓住杯子那一刻是什么样,跳过中间所有冗余帧,并基于这个想象同步生成抵达它的动作。
由于「事件」本身就是跨场景、跨物体的通用语义抽象,WALL-WM在跨场景泛化上也展现出明显更稳的表现。目前,这一模型已在论文
《WALL-WM: Carving World Action Modeling at the Event Joints》
以后小机器人们干活儿,也能更像人类一样抓重点,灵活应对物理世界的各种抓马情况了!
从按帧学动作,到按「事件」理解世界
这几年,主流VLA模型基本都在沿着一条路往前走:
给模型一帧当前画面,再加一句语言指令,让它预测接下来一段
这个做法当然很工程化,也确实方便训练,但问题在于真实世界的机器人动作,并不会乖乖按照固定时间窗口发生。
比如让机器人抓起一个杯子,它里面至少包含接近、接触、闭合夹爪、提起、移动、放下几个阶段。
每个阶段的物理状态都不一样,接触前和接触后更是完全不同的控制问题。
针对这个bug,自变量机器人在论文中提出了一个非常「反常识」的行业判断——
文本、视觉、动作这三类信息,其实是天然没办法「完全对齐」的
论文中提到,文本、视觉、动作在高维空间里有不同的
文本是高层、低熵的语义意图;视觉是连续演化的高维观察;动作则被物理世界强约束,对接触状态、时间精度和微小扰动都极其敏感。
如果直接把三者压进同一个共享空间,预训练表示很容易偏离原本的先验几何!!
所以说,这也是为啥目前行业内很多VLA在真机上视觉-语言-动作对齐的表现,远不如其底座VLM应有的⽔平…..
既然传统VLA问题这么多,自变量团队也重新追问了一个更为根本的问题:机器人到底该按什么单位学会一个动作?
基于这个思路,团队出了
世界模型,让机器人按event-centric的方式去训练和执行。
所谓的event-centric,简单说就是把机器人任务切在真正有语义、有物理动作变化的「事件边界」上,然后在这些事件数据上进行模型训练。
比如伸手、抓取、抬升、移位、放置,都可以看成一个个围绕动作展开的语义事件。
它能被语言说清楚,也能被视频完整记录,还能落到机器人的动作轨迹上,这样就可以把语言、画面和动作真正串了起来~
WALL-WM泛化能力更强的关键也就在这里:让机器人围绕事件理解世界变化,再把这种理解转成可执行动作。
而这,才是具身智能「世界模型」应有的形态。
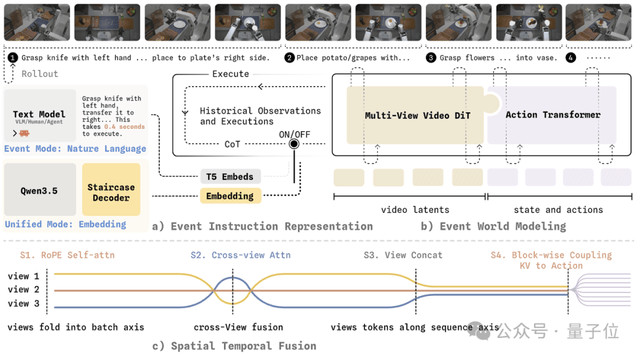
WALL-WM的核心链路:先预演,再执行
具体来说,WALL-WM做的不是直接从画面生成动作。
而是先让模型理解「下一个事件会让世界怎么变」,再把这种变化翻译成机器人该执行的轨迹。
背后是一整套从感知到控制的路径重构,自变量团队将其拆成了三层: