
\n
\n
\n
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
国产通用大模型第一梯队,来新人了?!
不卷参数,卷“智能密度×Token价值”
一张新面孔,就这样闯入了国产通用大模型第一梯队。
走的还不是行业主流的“堆参数”路径。
这事放今天,谁听了不想火速围观一下??
我也不例外,而且我还顺便挖了一下这家公司这样做的原因(好奇.jpg)。
结果你猜怎么着?答案居然如此“直击灵魂”——
再走传统老路,你我的Token钱包是真扛不住了
这事还得从过去几年行业默认的“堆参数、堆算力”玩法说起,得益于“大力出奇迹”这条法则,大模型确实变得越来越聪明,但账单也越来越离谱。
尤其进入推理时代、Agent时代后,这一问题肉眼可见变得更加突出了:
为了让模型“想得更深”,行业主流做法是让它把思考链条逐Token展开,结果Token消耗越来越夸张。
传导到行业参与者,企业开始天天愁赚不到钱,我们普通人也日常陷入“Token不够用、用不起”的焦虑。
所以,该怎么给大家精准止痛呢?
今天这位玩家,港股AGI第一股云知声,带着它的新一代基座模型U2,来了。
U2不卷参数,卷“智能密度×Token价值”。而且说是通用大模型,但骨子里其实是个原生智能体模型
说白了,U2的一切都是为了“让单位Token发挥出最大智能”而设计的。
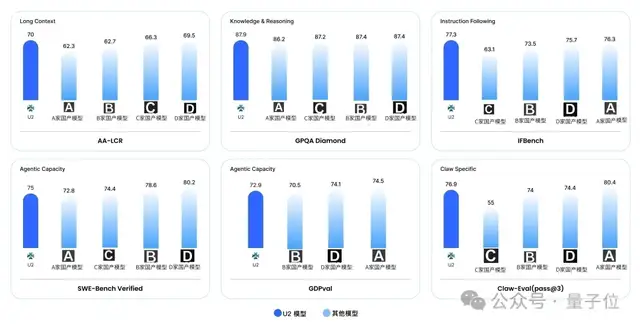
你问效果如何?数据很能说明问题:
U2在多项关键评测上,以极低的激活参数规模比肩甚至超越体量大得多的对手,思考Token消耗量可减少约25%,在压缩思考Token消耗的同时,推理成本显著低于同尺寸规模大小模型
能力不减、Token更少、成本还打下来了,U2到底是怎么做到的?
U2有多能打?实测一下
怎么做到的先不谈,咱先回答一个问题:这瓜保真不?(潜台词≈U2真实有多能打)
。和同类模型比,U2最明显的差异有两个:
一是特别能干活,IFBench指令遵循、Claw系列Agent评测、GDPval办公能力评测都打到了前排,而且完成复杂任务的交互轮次更少,不会动不动卡壳来回折腾;
二是“以小胜大”,GPQA硬核推理和长文本理解上,仅凭极低激活参数,打出了接近甚至超过部分超大模型的效果。
等于说,又能干活、又不靠烧算力,这两件事U2同时做到了。
好好好,我已经忍不住要用它跑跑真实案例了。
目前U2已正式上线云知声Token Hub,个人、开发者及组织均可体验
。它支持OpenClaw/Hermes等主流Agent脚手架,可无缝对接现有开发流程,适配成本较低。
既然U2擅长开发,一上来我就打算给它“挖坑”,出一道开放性题目(doge)。
做一个值得上Awwwards的前端demo,可自由选择创意主题,单文件HTML、不用外部库
这道题没有标准答案,考的是模型在没有约束时能主动展示多高的上限。
按照惯例,弱模型一般会选择做普通官网、卡片布局或按钮动画,而强模型会主动往粒子宇宙、流体模拟、物理引擎这个方向走。
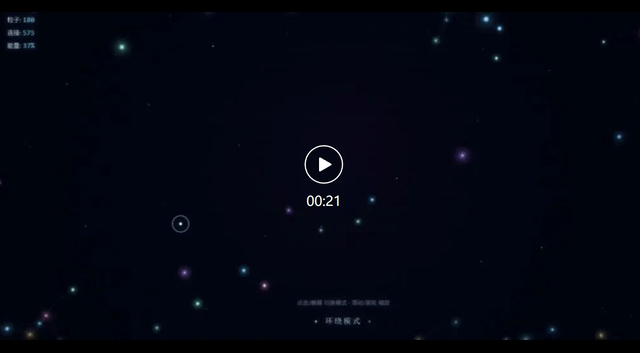
结果U2很快就交出了一个交互式粒子宇宙,将近1000行代码,没有引用任何外部依赖,全部原生实现
视频地址:https://mp.weixin.qq.com/s/IISZprE3c_4w0y61y0EBLQ
打开HTML,鼠标移动会扰动附近粒子的运动轨迹,点击会触发吸引、排斥、环绕三种模式的切换,左上角面板还能实时显示当前粒子数量及运动状态。
日常感慨一下,以前考大模型,顶多是让它在六边形里转小球。现在倒好,直接上这种生产力级的Vibe Coding了。
而说到Vibe Coding,最近刚好有个想法想实践一下:
做一个12星座版的《TA到底在想什么》应用
网上冲浪时经常刷到那种,求网友帮忙分析“crush到底什么意思”的帖子,脑瓜子一转,商机这不就来了。