
\n
\n

\n
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
机器人原生世界动作模型问世!首创时空一体架构,复旦系团队出品
量子位 | 公众号 QbitAI
通用人工智能的战火,已经彻底从虚拟的数字空间,一路烧到了真实的物理世界。
,已经成为当下整个AGI赛道最卷、也最核心的决胜高地。
当前行业主流的VLA视觉语言动作模型、通用世界模型、视频推演方案,普遍存在空间感知精度不足、物理逻辑约束缺失、长时序规划能力薄弱、真机落地鲁棒性差等一系列痛点,无法支撑机器人实现真正的自主感知、自主推理、自主决策与稳定交互。
在物理AI产业快速迭代的关键节点,深耕世界动作模型底层技术五年的
复旦系科创企业眸深智能
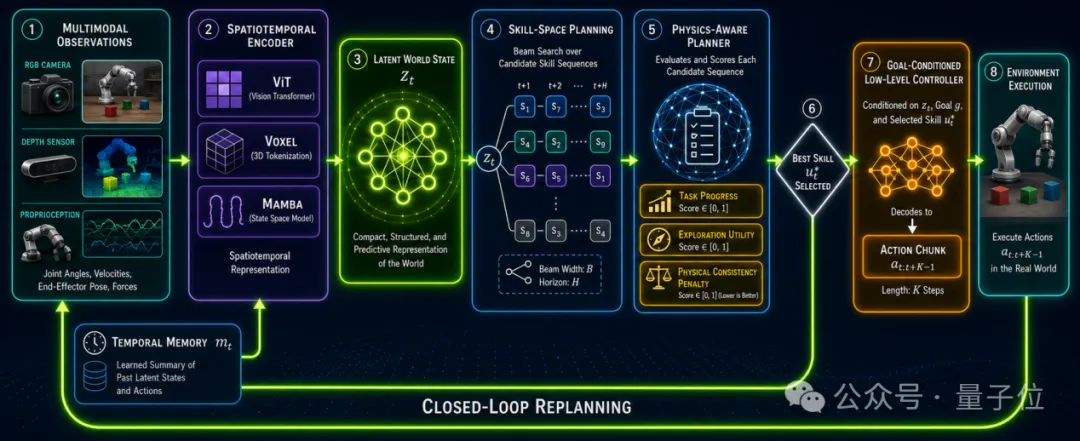
STI-WM时空一体世界动作模型(Spatiotemporally Integrated World Model)
专为机器人原生打造的通用具身大脑
,该模型以时空一体化建模、物理一致性约束、端到端原生融合为核心,彻底打破传统模型的技术桎梏,开辟了物理世界AGI落地的最优技术路径。
复旦+英特尔+英伟达,硬核学术成果稳居全球第一梯队
眸深智能的技术突破,源于长期深耕的学术积淀与全栈工程能力。
公司核心团队源自复旦大学深度学习实验室,构建了
学术科研、工程落地、产业商业化
三位一体的顶级团队架构:
由复旦大学未来信息创新学院教授、深度学习实验室主任
坐镇科研底层,原英特尔中国首席科学家
的技术负责人掌舵工程化落地,95后复旦连续创业者
主导商业化布局,形成实力强劲的“复旦铁三角”核心阵容。
核心研发人员来自复旦大学,汇聚百余名校硕博人才,自2021年行业风口未至之时,便前瞻性布局世界模型、三维感知、时序动作生成三大底层核心技术,持续深耕技术攻坚。
全球顶尖赛事冠军与顶级学术荣誉
推出全球首个人形动作生成大模型MotionGPT、三维世界模型HL3DWM;
拿下ICCV2023全球三维目标识别冠军、CVPR2024三维密集语义推理冠军,斩获IJCAI2025杰出论文奖,是
近五年国内唯一斩获该奖项的具身智能团队
,团队技术负责人斩获2025年中国具身智能新秀EAI榜单20强。
其原创技术成果被英伟达DAIR等国际顶尖实验室引用,学术创新与工程落地能力稳居全球第一梯队。
重构行业技术范式:5年沉淀,开创并引领世界动作模型路线
当前行业多数方案仍采用
通用世界模型+VLA拼接
的改良模式,模态割裂、信息损耗严重,缺乏真实物理世界约束,只能实现“视觉合理”,无法适配机器人真机落地的真实需求。
眸深智能从AGI本质出发,率先确立
世界动作模型原生融合路线
机器人与物理世界的一切交互,最终都落地为动作,唯有精准理解时空演化规律、遵守物理逻辑、实现端到端原生映射,才能真正解决机器人泛化性差、落地难的行业顽疾。
早在2022年,团队便创新性提出
全球首个影空间语言-动作端到端映射MLD模型
,成果发表于CVPR 2023,该核心思路在2025年5月被英伟达DAIR实验室核心工作引用验证。
历经五年迭代,团队已完成
,在多模态端到端融合、高精度动作生成、时序逻辑推演领域积累深厚,动作精度、推理速度、任务泛化性持续领跑行业。
机器人原生架构四维统一,破解真机落地核心痛点