
\n
\n
\n
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
τ0-WM:最大规模预训练的开源具身世界模型来了
17800小时的真机数据
henry 发自 凹非寺
量子位 | 公众号 QbitAI
具身智能火了快两年,现在,终于有团队富裕到拿真机数据去砸预训练了。
这是啥概念?差不多相当于一台机器人,连续两年、一天24小时不停地被人类遥操作。
当所有人都以为真机数据是奢侈品,难以scaling,只能放在最后的微调阶段时。
刚刚,上海创智学院副教授、智元机器人首席科学家
全球最大规模的开源预训练具身世界模型
τ0-World Model(τ0-WM)
整个τ0-WM参数量达到
,预训练数据规模高达约3万小时。其中,
真机遥操作数据第一次成了绝对主力
,占到了1.78万小时。
而3万小时的预训练数据,是目前全球开源预训练具身世界模型中最大的。
τ0-WM不仅能像其他世界模型那样预测未来画面、生成动作。
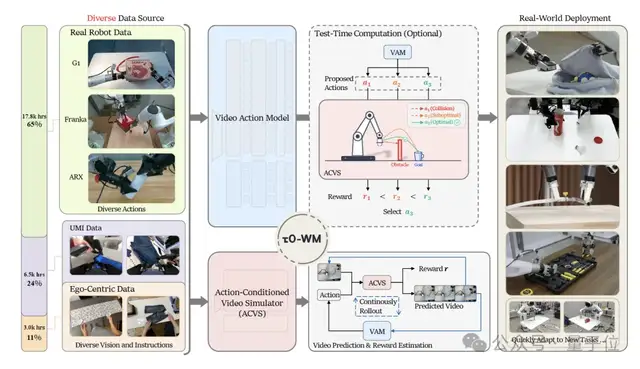
更重要的是,它还结合了测试时计算(Test-Time Computation),让机器人在执行前对多个候选动作进行排序,选出最优方案,质量不够就调用模拟器修正后再执行。
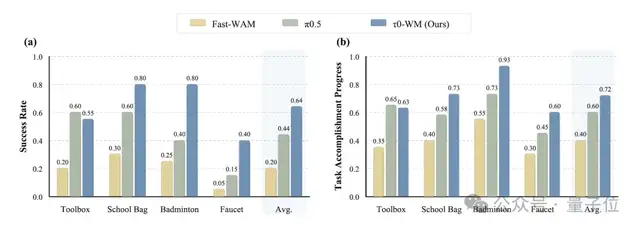
基于这套方法;τ0-WM在四个长程精细操作任务,包括Toolbox(工具收纳)、School Bag(书包装物)、Badminton(羽毛球装盒)和Faucet(水管接头对接)的平均成功率超过了对标π0.5和Fast-WAM。
可以说,罗剑岚团队此前在后训练方面的持续投入,不仅攒出了足够规模的真机数据,也攒出了把这些数据用于大规模预训练的经验。
预训练和后训练这两条线,终于对齐了。
提议、模拟、评估,然后行动
过去几年,驱动机器人实现感知与控制的主流范式,大多是一种反应式的端到端策略:
神经网络看到画面,立刻输出动作。
这种类似于人类“条件反射”的方式,在抓取、放置等标准任务里已经非常成功。
但就像人类其实并不完全依赖肌肉记忆一样,机器人在面对接触密集、长程跨度、或者存在严重遮挡的复杂操作时,单纯依靠“看见场景就输出动作”的方式,也很容易导致不可逆的错误。
很多时候,一步错,后面可能就全错了。
所以,和许多世界模型方法一样,
选择让机器人在行动之前,先在脑子里“想象”一下:
如果自己执行了这个动作,未来会发生什么,环境会怎么变化。
但τ0-WM特别的地方在于,它不只“想一次”。
为了让机器人能够三思而后行,研究引入了Test-Time Computation(测试时计算),让机器人在真正执行前,可以多花一点时间,在内部“虚拟沙盘”里并行想象很多次,反复比较,甚至主动纠错。
也就是说,τ0-WM让机器人不再只是看到画面就立刻出手,而是像人一样,先在脑子里盘一遍哪种路线更靠谱,再决定真正怎么做。
某种程度上,这其实是在让机器人学会一种“慢思考”。
具体来说,τ0-WM的在线推理,分成三步。
首先,视频动作模型(VAM)会根据当前多视角观测、语言指令以及机器人状态,一次性采样出多组候选动作,同时生成对应的模糊未来画面。
这相当于机器人先在脑子里快速闪过几种可能的做法。
其次,动作条件视频模拟器会针对每组候选动作,进一步生成对应的多视角未来画面。
之所以是多视角,是因为真实机器人操作里,正面视角经常会被机械臂或物体挡住,所以模型必须还能“脑补”侧面、顶部等其他视角下的未来状态,才能真正判断动作后果。
最后,系统会先用RCS(Re-denoising Consistency Score)给动作打分:把候选动作重新加噪,再丢回模型重新去噪,观察重建误差。