
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
一次吃下一本书!百度开源新OCR,作者疑似前DeepSeek研究员
henry 发自 凹非寺
量子位 | 公众号 QbitAI
国产开源OCR又刷新SOTA!
刚刚,百度开源了全新的OCR新模型——
Unlimited OCR
它主打一口气读完几十页长文档,并在OmniDocBench上刷新SOTA,整体成绩超过此前的DeepSeek OCR。
与传统OCR处理长文档时“一页一页读,再把结果拼回去”的思路不同,Unlimited OCR这次模仿了一种酷似人类抄录员的工作方式:
不再死记硬背前面已经抄写过的内容,而是只保留当前工作需要的信息和进度。
基于此,它能够像人一样连续阅读整本书,而不是每读完一页就中断一次,再从下一页重新开始。
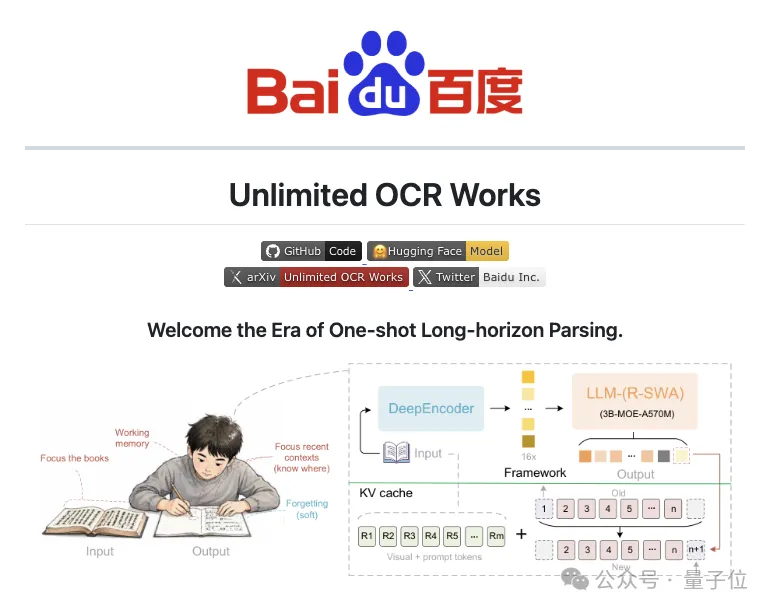
更关键的是,借助创新的
参考滑动窗口注意力(Reference Sliding Window Attention,R-SWA)机制
,即便文档越来越长,显存占用和注意力计算开销也几乎不会增长。
for-loop只是权宜之计
要理解Unlimited OCR,得先看看传统OCR是怎么处理超长文档的。
简单来说,OCR(光学字符识别,Optical Character Recognition)就是把图片里的内容读出来,再转换成Markdown等可编辑文本。
在以往的处理流程中,一张图片会先进入编码器,被压缩成一串视觉Token;随后解码器再一个字一个字地把内容写出来。
但问题在于,传统的OCR解码器每生成一个新Token,它都需要回头查看之前生成过的所有Token,再决定下一个字该写什么。
于是文档越长,需要回看的历史内容就越多,KV Cache持续膨胀,显存占用和注意力计算开销也随之增长。
最终,无论是生成长度还是推理速度,都会受到限制。
这也是为什么现有OCR系统很难一次读完几十页文档,通常只能采用“逐页处理+结果拼接”的方案:
每读完一页就重置上下文,最后再由外部程序把结果重新拼起来。
这种for-loop式方案虽然工程上可行,但本质上只是权宜之计,而Unlimited OCR想解决的,正是进一步扩展模型在长程任务的表现。
如果不采用逐页重置的for-loop方案,模型又该如何在保持连续阅读状态的同时,避免KV Cache随着文档长度无限增长?
Unlimited OCR给出的答案,不是让模型记住更多东西,而是让模型学会像人一样“遗忘”。而这,就引出了它最核心的创新点:
为了说明参考滑动窗口注意力的设计思路,研究举了一个非常形象的例子:
人类阅读长文档其实并不是全量回溯的。
比如抄写一本书时,你不会每写一个字都重新翻阅前面几十页。
你只会保留当前的阅读状态,以及刚刚写下的一小段内容,用来确认没有跳行、没有漏字,更久远的信息则会逐渐淡出记忆。
软遗忘(Soft Forgetting)
受此启发,参考滑动窗口注意力应运而生。
对于每个待生成Token,模型始终关注全部参考Token(Reference Tokens),也就是视觉Token和提示词;
与此同时,在输出端只保留最近n个历史Token(默认128个)参与注意力计算。
就好像你抄书的时候,原书始终摊开在桌面上,可以随时查看完整内容;
而手边只保留最近写下的几行字,用来追踪当前进度。更早的内容则自然淡出工作记忆。
这样一来,模型既能持续看到完整图像,又能依靠局部历史信息判断当前解析到了哪里。
此外,这里值得一提的,还有Unlimited OCR的KV Cache管理方式。
论文将KV Cache设计成一个固定长度的队列。每生成一个新Token,最旧的一部分状态就会自动移出,新状态再补进来。
因此,无论最终生成几千还是几万个Token,KV Cache规模始终保持恒定,显存占用和计算成本都不会继续增长。
这也是R-SWA与其他注意力机制最大的区别。
相比全注意力(Full Attention),后者的KV Cache会随着解码不断膨胀,而R-SWA始终保持固定大小。
相比传统滑动窗口注意力(SWA),后者会把视觉Token和文本Token一起放进窗口,随着窗口不断滑动,早期视觉信息会逐渐被挤出;解码越长,对原图的感知就越模糊。
而R-SWA则将视觉Token单独保留下来,让它们始终作为参考信息存在,不参与滑动窗口更新。
换句话说,图像始终保持清晰,发生滑动的只有输出文本本身。
正如上图所示,传统OCR越读越慢,而Unlimited OCR基本保持匀速运行,这正是R-SWA的价值所在。
在实验部分,研究团队采用OmniDocBench v1.5和v1.6评估模型的文档解析能力,并额外构建了覆盖2页至40页以上文档的内部测试集,专门考察其长文档连续解析能力。
在OmniDocBench v1.5上,Unlimited OCR取得了
的综合得分,相比DeepSeek OCR提升
在最新的v1.6版本中,成绩进一步达到93.92%,刷新当前SOTA。