

< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
GPT-5.6突然发布!Fable5痛失最强基模王座
一口气端出三款GPT 5.6系列模型
量子位 | 公众号 QbitAI
ChatGPT史上最强模型来了!
就在刚刚,OpenAI一口气端出三款
GPT 5.6系列模型
主打一个全家桶「多款齐发」——
(大地)、低成本高速款
GPT-5.6 Sol:
最夯模型,编程测试左踢自家模型GPT5.5,右打隔壁Fable 5,还新增max/ultra两个模式。
△GPT-5.6 Sol编程评测表现
GPT-5.6 Terra:
面向日常工作,性能对标GPT-5.5,同时价格便宜约2倍。
GPT-5.6 Luna:
GPT-5.6系列里最快、最便宜的一档,同时保留较强能力~
看完内心os:你别说哈,这新模型确实夯啊…
普通用户目前无缘使用ing!!!是的,人家玩《有限预览》那套了…
目前新模型只给少数受信任的「合作伙伴」提供了有限的预览版本。
普通用户可能得等等等等等等*100。(doge)
熟悉的配方,熟悉的操作。
Fable 5:我不知道您这是怎么了,这波咋瞅都像冲着我来的呢???
GPT-5.6 Sol、Terra、Luna三款模型齐发
是的,这次人家模型的名字开始走起天文学宇宙感路子了。
从产品定位看,三者分工很清楚——
Sol冲旗舰能力,Terra打日常主力,Luna负责速度和成本。
在价格上,则按每100万token计价:
Sol输入5美元、输出30美元;Terra输入2.5美元、输出15美元;Luna输入1美元、输出6美元。
先看这次发布的OpenAI史上最强旗舰模型——
在能力上,Sol面向的是
高难度推理、复杂代码、生物、网络安全等长链路任务
尤其适合需要规划、迭代、调用工具、协调步骤的复杂工作流。
而且非常值得一提的是,OpenAI还给这新模型搞上了「加餐」——
让模型获得更长的深度推理时间的
,以及可以调用多个subagents协同处理复杂任务的
要知道但凡加上ultra俩字估计就不简单……
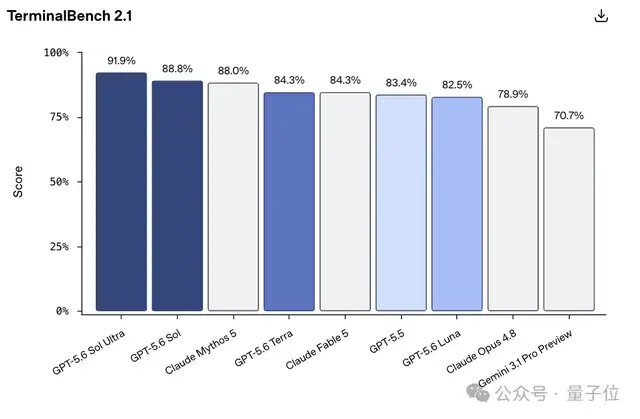
这不嘛,吊打Fable 5的
基准测试就水灵灵地来了,人家在Terminal-Bench 2.1上创造了新的SOTA。
ultra模式下比Fable5高出去7.6个百分点,比上一代GPT5.5高出9.4个百分点——
,GPT-5.6 Sol在GeneBench v1上也强于GPT-5.5,而且使用token更少。
这个测试评估的是长链路基因组学和定量生物分析任务,说明Sol在科研类复杂任务上的效率也有提升~
方向,OpenAI称Sol是其目前网络安全能力最强的模型。
在ExploitBench上,GPT-5.6 Sol已经能接近Mythos Preview的表现,同时只使用约三分之一的输出token:
而在由加州大学伯克利分校研究人员与OpenAI及其他前沿实验室合作开发的ExploitGym测试中——
Sol、Terra、Luna三款模型都会随着推理强度增加,在网络安全能力上出现明显提升~
Terra的定位更接近GPT-5.6系列里的日常主力模型,OpenAI给出的说法是,Terra性能与GPT-5.5具备竞争力,同时价格便宜约2倍。
最后走速度和成本路子的
,则是GPT-5.6系列里最快、最便宜的一档。
它面向的是高频、低延迟、成本敏感任务,比如轻量问答、简单信息处理、实时交互、批量自动化等场景。
需要提一嘴的是,除了Sol外,Terra和Luna目前公开披露的benchmark信息相对有限的,后续可以蹲蹲这俩模型的评测表现!