< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
世界模型来了因果技术标杆!具身大脑真要长脑子了
量子位 | 公众号 QbitAI
具身智能正在经历一场普遍的“水土不服”。
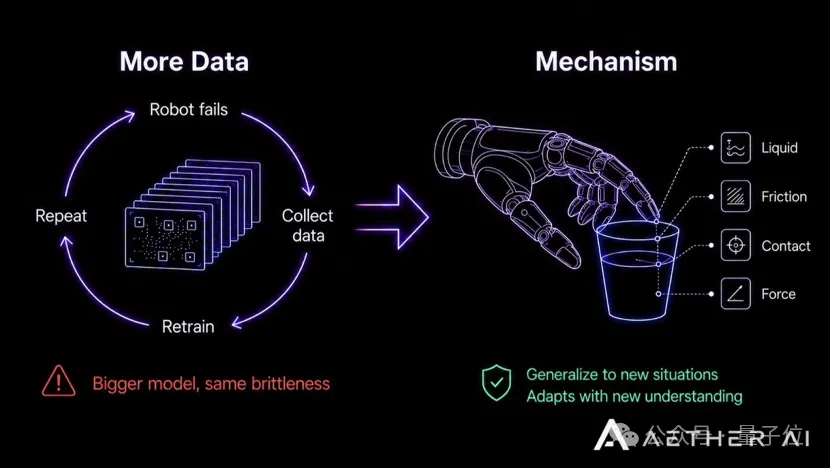
很多人发现,在模拟环境里表现优异的机器人,一旦进入真实工厂,往往立刻失灵。这是行业内最尴尬的现状,也是整个具身赛道最核心的瓶颈:
换一个环境,可能就要重新采数据、重新训练、重新交付。机器人学的始终是特定场景下的“经验”,而非现象背后的“规律”。
在这一背景下,为了让机器真正理解物理世界,构建“世界模型”逐渐成了具身大脑近年来最拥挤的赛道,各式技术路线层出不穷。
最近,有一家成立不久的公司——
,宣布完成2000万美元种子轮融资,由经纬创投领投,英诺基金、SWC Global、九合创投参投。它的路线在业内几乎是独一份:不做视频生成,不做3D重建,也不做JEPA,而是走了一条少有人走的路:
如今的主流大模型,本质上都是基于数据表层的相关性,而非底层的因果性,这在物理世界可能行不通。
简单来说,它的因果世界模型想让机器人像人类一样,真正理解背后的机制和“为什么”,而不仅仅是推测“接下来最可能发生什么”。
如果将LLM、VLA、视频生成模型等技术路线比作拼体格的相扑选手,力量来自更大的算力、参数和数据,因果世界模型更像是在练内功,通过底层的理论突破,试图用更少的数据实现更强的泛化,“四两拨千斤”。
都叫世界模型,但彼此并不一样
先厘清一个问题:都以“世界模型”命名,因果世界模型和其它世界模型有什么区别?
Aether AI创始人、加州大学圣地亚哥分校(UCSD)助理教授黄碧薇,将当前行业内主流世界模型分为三条路线:
:像素级渲染效果确实惊艳,但问题在于它拟合的只是画面的表层相关性。画面看上去合理,不代表物理上可行。一个杯子可以凭空穿过桌面,只要像素过渡平滑,模型就不会觉得有什么不对。这种路线做视频可以,做精准控制不行。
:空间结构还原得很好,但它本质上是一个静态的世界快照。时间维度上的动力学、因果交互,这一块基本是缺失的。知道物体在哪,不等于知道它会怎么动、为什么动。
:去掉像素解码器,在隐空间做状态转移,思路很巧妙。但它没有显式地去拆解因果变量和结构,像摩擦力、接触力这类精细交互信息,很容易在抽象过程中被丢失。
这些技术路线都在回答同一个问题:AI如何建立对现实世界的内部表征。但黄碧薇追问的是更底层的那个问题:
物理世界为什么这样演化?
因果世界模型是第四条路线
,侧重在隐空间显式学习因果变量、结构、动力学,掌握底层物理规律。
它关心的不只是“下一步最可能发生什么”,还有“是什么导致了下一步的发生”。
在黄碧薇看来,因果世界模型才是世界模型的“终局形态”,是实现物理AGI的最优技术路线。
进一步拆开来看,因果世界模型包含三大核心要素:
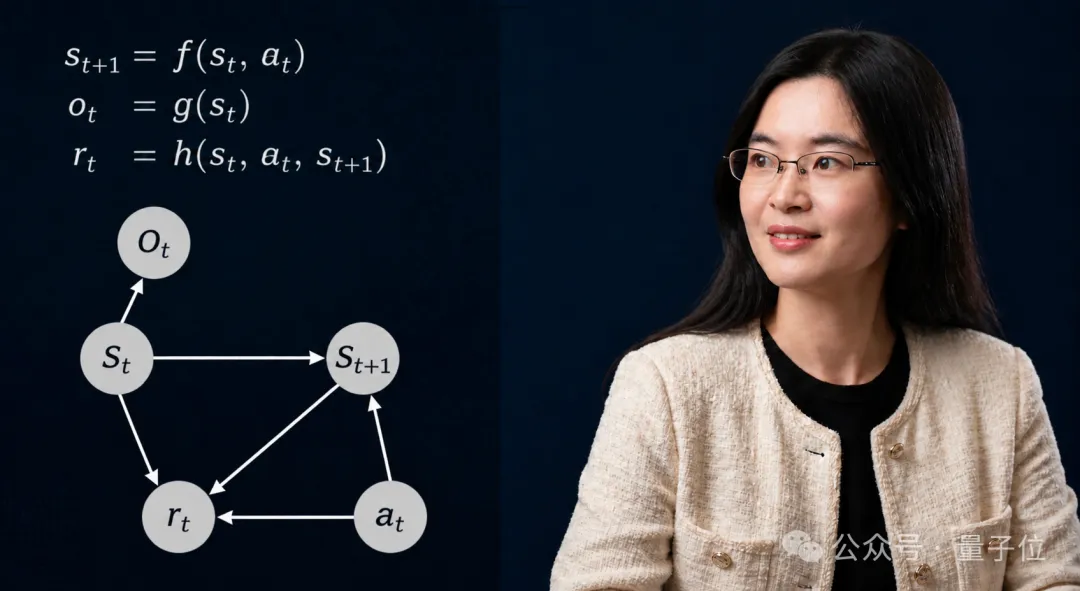
。从像素、传感器这些原始数据里,拆出真正独立的因果特征——物体的形状、速度、角速度、摩擦力系数、表面粗糙度等等,这些变量是物理交互的基本单元。
。建模不同变量之间的影响关系。手施加的力、角度、速度,如何共同决定抓取的成功率?这里没有”端到端”的黑箱,结构是显式的,可解释的。
。学习系统统随时间、动作的状态转移规律,这不是在拟合轨迹,而是在学习支配轨迹的规则,预测不同动作下下一时刻的世界状态。
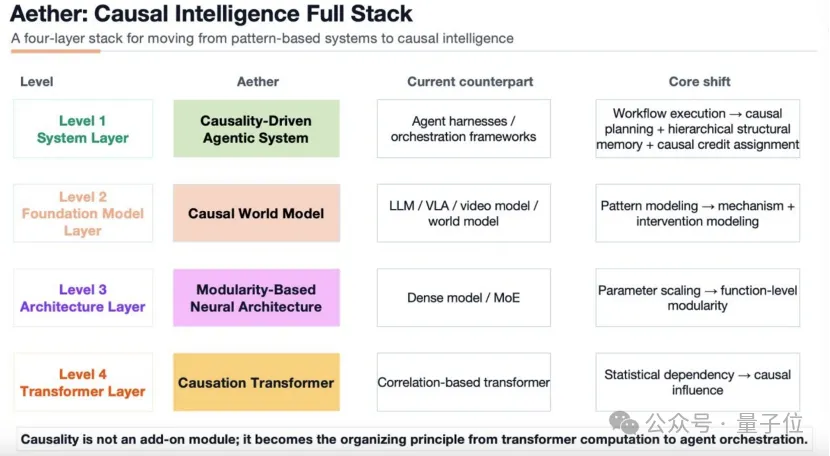
从完整的系统层面,Aether AI有四层架构:底层依然是Transformer——没有重新发明轮子,因果并不排斥Transformer;中间层是因果世界模型和模块化架构(类似MoE);最顶层是Agent系统。
这套架构被称为“因果AI全栈架构”,从Transformer到Agent,需要注意的是,
它不是给现有模型加因果“插件”,而是从Transformer到Agent系统,全部由因果思维驱动。
还有一点很关键:相较于VLA、WAM等其它模型,
因果世界模型对数据几乎没有额外的要求。
Aether AI约80%数据使用的是模拟、第一视角和公开视频数据,约20%使用遥操数据完成“最后一公里”。
面对同样的数据,因果模型能从中提取出相关性模型读不出来的深层信息。
实现这一点,靠的是因果世界模型背后的数学和统计理论,这恰恰也是其技术门槛所在。
从“找规律”到“懂原理”
熟悉AI的人都知道,过去几年,LLM的成功让行业形成了一种朴素信仰:大力出奇迹,数据、算力、参数堆上去,智能就会涌现。
这套逻辑在语言世界确实奏效。原因很简单:人类文明几千年的知识已经被压缩成了文字,模型只需要把语义表层的关联学到极致,就足以显得“智能”。
但物理世界不提供这种便利。