

< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
具身智能Skill时刻!英伟达开源机器人技能库,Jim Fan:范式变了
henry 发自 凹非寺
量子位 | 公众号 QbitAI
6!机器人也能学Skill了。
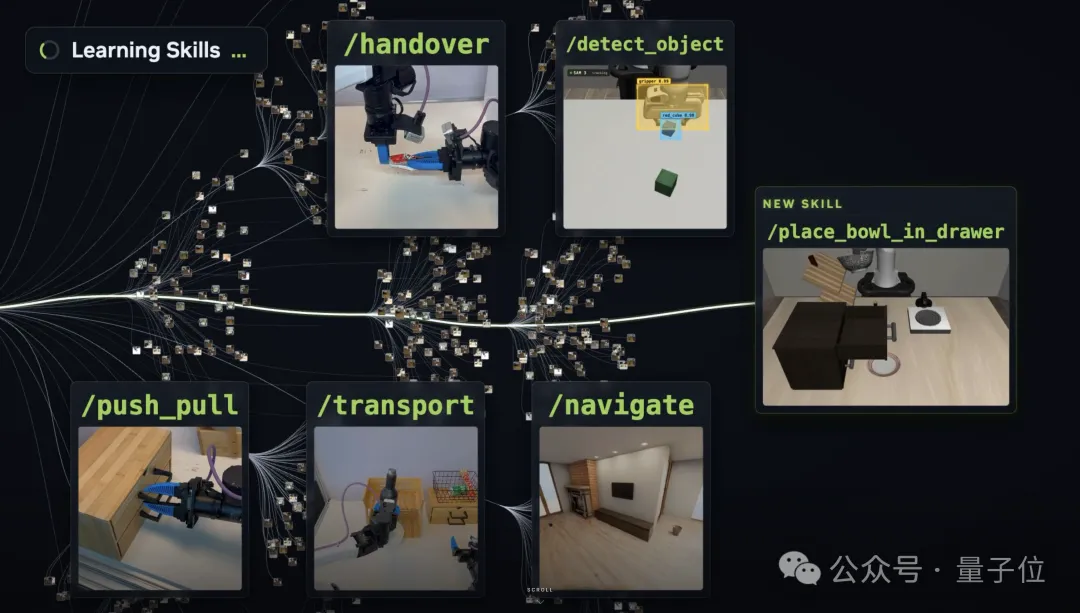
一套能让机器人持续成长的技能库
简单理解,ASPIRE有点像一个机器人版Coding Agent。
就跟GPT能把你的prompt、工作记录炼成可复用的skill一样,它也会把机器人的一次次失败和修复,沉淀成之后能继续调用的经验。
只不过,它review的不是代码,而是机器人的
每当机器人执行任务时,ASPIRE就会把感知、导航、抓取、碰撞、运动规划这些过程都记下来。
它背后调用的GPT / Claude则会像研究员一样,判断任务中哪里出了问题,迭代程序。如果跑通,就把沉淀出来的经验写进Skill。
由此,机器人就可以通过写代码、看执行轨迹、修程序、沉淀技能来持续学习。
而这,可不光是在机器人经验中炼化Skill这么简单。
还表示ASPIRE代表了一种全新的
训练,从梯度下降变成了不断打磨技能(Skill Refinement);
训练好的模型,对应的也不再只是一堆浮点权重,而是一个持续扩展的机器人技能库(Sensorimotor Skills);
分布式训练,则变成了一群 Agent 各自练习不同技能,再把经验汇总进同一个技能库。
训练出来的,不一定是权重
虽然开头已经介绍的七七八八,但在讲怎么革新机器人训练范式前,咱先啰嗦几句背景。
Agentic Skill Programming through Iterative Robot Exploration
它能让机器人用代码执行任务,失败后看多模态执行轨迹,再修程序,把修好的经验存进一个不断变厚的skills library。
这里的Skill,虽然本质上还是一段喂给大模型的上下文,却沉淀着一套经过验证的代码修复经验(Code Repair Pattern),让机器人知道遇到某类问题时,该如何修改控制程序。
比如,当机器人准备拿起一个收音机时,已经识别到了目标,却始终无法靠近时。
Agent能分析出来原因并非识别错了,而是规划器(Planner)给出的目标点都落在障碍物的碰撞缓冲区内。
由此,ASPIRE就会在这次经验的基础上,总结出一条新的Skill:
如果遇到这种规划失败,就尝试从45°、90°、180° 等不同角度重新接近目标,直到找到一条无碰撞路径。
以后再遇到类似场景,无论目标变成收音机、微波炉还是其他家具,这条经验都可以直接复用,不必重新试错。
说到这,你可能会好奇。 机器人训练,不应该都是搞数据、梯度下降、模型权重、真机采集、仿真到现实迁移吗?
怎么就突然成攒skill了?
这里要先讲一个最近很火的范式,
Code as Policy
跟VLA等端到端的策略模型不同,Code as Policy不让模型直接输出机器人动作,而是让大模型写一段可执行的机器人控制程序。
程序里可以调用感知模块、规划API和控制原语,比如识别物体、规划路径、移动机械臂、执行抓取。
这样一来,机器人行为就不再完全藏在神经网络权重里,而是变成了可执行的操作代码。
有了代码,就可以被现在强的离谱的Agent模型检查、修改、调试、继续优化。
但过去,Code as Policy一直有两个问题。
第一,机器人失败了,系统通常只知道“任务没完成”,却不知道到底是感知错了、抓取没抓稳、路径规划撞了,还是恢复动作出了问题。
第二,也是更关键的一点,
一个任务做完,调试过程中发现的修复方案、恢复策略、prompt写法就被丢掉了,下次遇到类似问题,还得重来一遍。
这也是为啥Jim Fan说:
(有了ASPIRE)当机器人完成第100个任务时,它终于不再像完成第1个任务时那样一无所知。
说白了,这整个过程就跟人类机器人工程师一样:
当一个机器人程序失败后,工程师会回放执行过程,看感知结果,分析运动轨迹,判断到底是抓取错了、规划错了,还是某个恢复动作没接上。
修好之后,工程师会记下这次的经验。下次再遇到桌边物体、抽屉把手、窄空间导航,就不会再从零开始。
而ASPIRE做的,就是把这套经验积累机制交给agent。它不只是让大模型写机器人代码,更让大模型在执行环境里
反复试、反复看、反复修
,最后把验证过的修复经验沉淀成Skill。
所以,在ASPIRE里,训练已经不只是梯度下降。
训练过程变成了Skill Refinement;训练产物,也不只是模型权重,而是一个机器人不断积累、不断成长的Skills Library。
三阶段pipeline