
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
全球首个:隐空间世界模型,打通长时序双向物理因果链了!
刚融了2亿美元,冲到了具身榜单第一
量子位 | 公众号 QbitAI
你从桌上端起一杯水,大脑用了
估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。
在这个动作中,你的大脑不会在意杯子上的花纹,或是杯壁折射出的复杂光影,而是能瞬间抓住核心:
手要出多少力,水才不会晃出来
正是这种忽略无关的环境细节、
直接洞察本质的“物理直觉”
,让我们干起细活来行云流水。
但对机器人来说,想要学会这种对物理世界的因果直觉,基本属于具身智能领域的高难度悬赏题。
现在,一家成立仅一年的具身智能新锐——
,直接带着新解法交卷了。
全球首个“长时序双向物理因果链”隐空间世界模型MWA™
,拓展具身智能的多元场景泛化能力,直击机器人长周期、高精度执行的行业老大难问题。
在由斯坦福大学等顶尖机构联合发起的RoboCasa GR1 TableTop榜单中,无界动力MWA™以
75.2%的平均任务成功率拿下全球第一
英伟达GR00T-N1.6
作为赛道里的新晋选手,无界动力是行业里少数坚持
“隐空间世界模型 + 强化学习”
这条略显特立独行的硬核路线,不仅在技术实测上跑通了闭环,在资本市场也展现出了极强的吸金能力:
超2亿美元的天使轮融资
,而紧随其后的Pre-A轮近
也已接近尾声,背后站着红杉中国、线性资本、京东关联基金等一众头部重仓机构。
这只既能打、又吸金的行业黑马,究竟是如何帮机器人看清物理因果、打破多场景泛化瓶颈的?
通向终局的路线:隐空间世界模型 + 强化学习
懂了语言和逻辑,机器人就能在现实世界里听懂话、能干活了吗?
过去几年,VLA(视觉-语言-动作)具身智能路线,虽然让机器人听懂了人类的文本指令。
但一到现场,只要光照稍微变一下、桌上的杯子挪个几厘米,机器人就会瞬间“卡壳”甚至动作变形。
本质原因在于,传统VLA模型让机器人干活,更像是一场“刻板的开卷考试”。
它们极度依赖人类演示的模仿学习,只是在死记硬背人类演示的动作轨迹,底层根本不理解物理世界的因果关系,泛化性自然出现断崖式下跌。
人类能处理各种非标任务,靠的是大脑天然具备对物理世界的“直觉推理”。如果机器人对现实的常识认知一片空白,其策略上限就会被锁死在旧范式里。
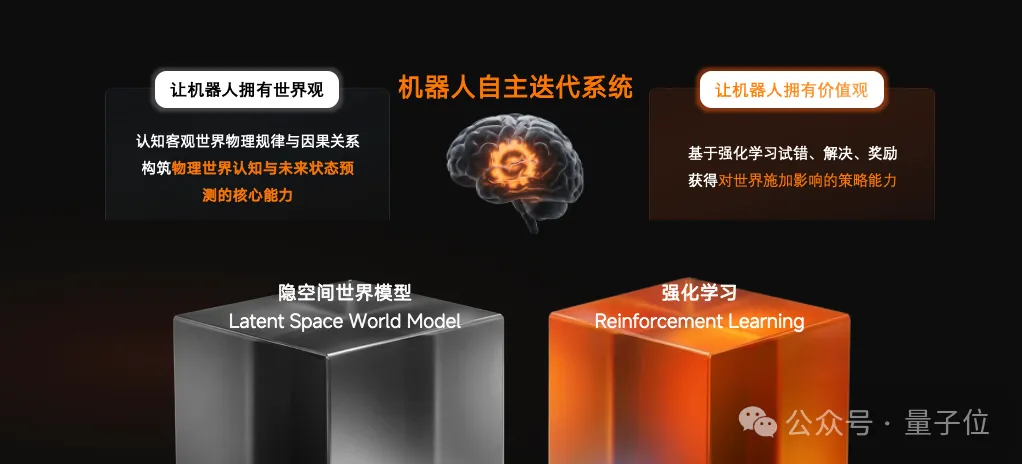
无界动力选的是另一条路线:
隐空间世界模型 + 强化学习
建立“世界观”,负责让机器人认知物理规律与因果关系,构筑起对物理世界认知与未来状态预测的核心能力。
则塑造“价值观”,通过高频试错与奖励反馈,负责把对物理世界的理解转化为精准的执行策略。
先看懂因果,再学会行动。只有让机器人看清物理世界的因果边界,它才能真正跨越实验室Demo,到多元场景里下场干活。
机器人如何懂物理?别盯像素,去抓环境变化的“潜动作”
但要建这个世界模型,随之而来的第一个问题是:
传统路线在推演未来时,往往在像素空间里做预测。
机器人看一段视频,不仅要学手怎么去抓杯子,还要顺便把背景里光线的微妙变化、无意义的像素噪声、甚至地板的纹理全算一遍。
大量算力浪费在了与任务无关的冗余信息上。
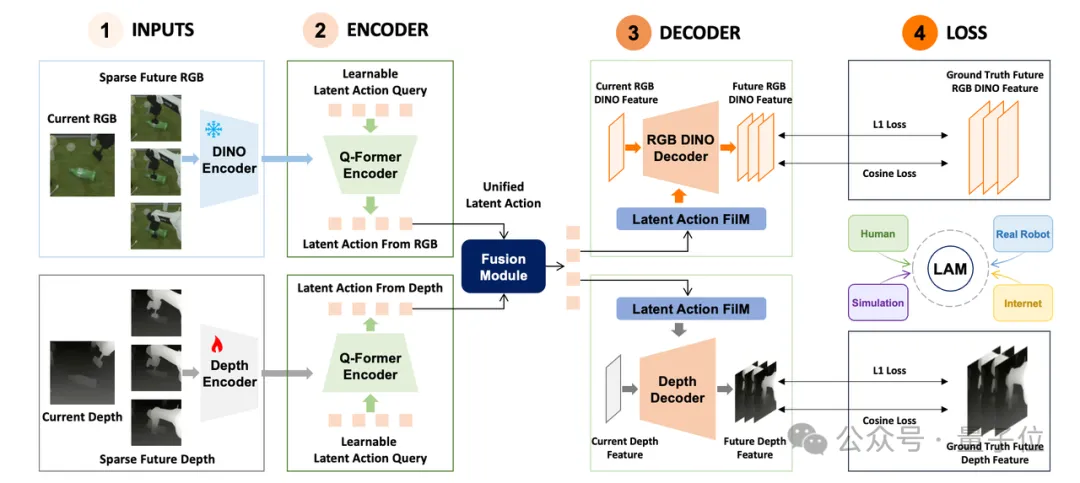
无界动力的MWA™全程在
统一共享的隐空间(Latent Space)
内完成推演,跳过像素层面的冗余计算。
更关键的是,它提炼出了
“潜动作(Latent Action)”
,作为场景交互变化的底层表征。
传统具身智能依赖显式的动作空间,需要人类事先标记好机械臂末端走到哪个位置、关节沿什么轨迹转动,标注成本极高。