

< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
训练世界模型,开始从人类的肌肉和脑子里偷师了
具身智能数采迎来了新范式
量子位 | 公众号 QbitAI
具身智能数据的竞争,正在从“量大管饱”进入下一关。
过去一年,第一视角视频成了机器人训练的主流燃料。人戴上相机做饭、整理桌面、开抽屉,就能产出大量操作样本。
数据量的问题初步缓解,但一个更深的缺口浮出来了:
这些视频只记录了人做了什么,没有记录人为什么这样做,更没记录动作执行中大脑和身体如何实时修正。
FaceMind脸谱心智
想填的,就是这个缺口。
这家由两位95后博士创立的公司,提出了一套全新的
Ego-NeuroLoop
它同时采集四类信号,把人类完成一个动作时“看哪里、准备做什么、肌肉怎么发力、反馈怎么修正”的完整闭环,压进同一条时间轴。
NeuroMatrix
负责降低采集门槛,信号处理层
NeuroBooster
负责把噪声拉满的原始数据对齐成模型能“吃”的格式。
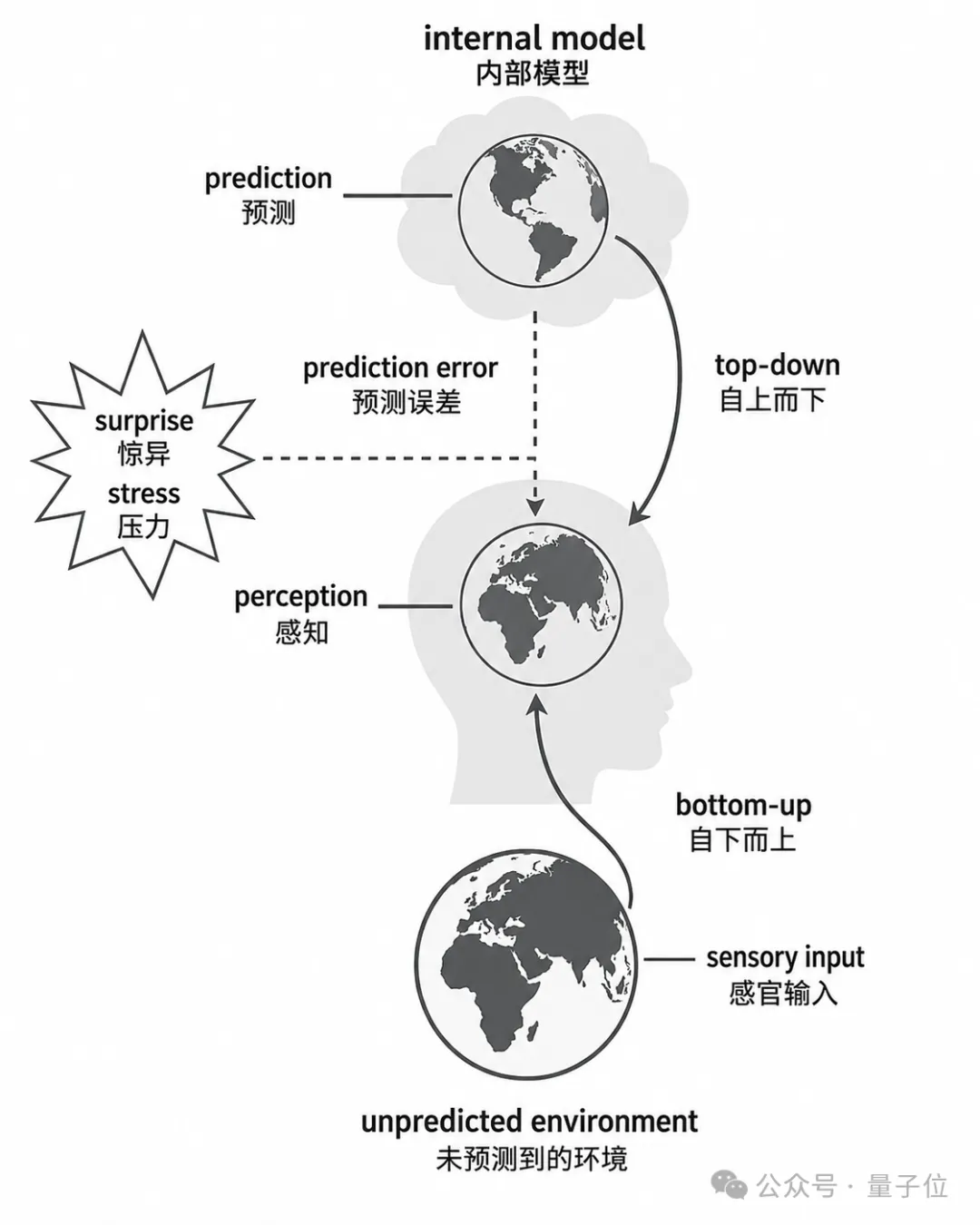
而这一整套思路的起点,来自神经科学里一条被反复验证的理论:贝叶斯大脑。
贝叶斯大脑:大脑一直在预测世界
神经科学里有一条被反复验证的理论,叫
,常和预测处理、自由能原则放在一起讨论。
它的核心思想是,大脑不是被动接收信息的容器,它一直在
。基于过去经验和当前上下文,大脑会对外部世界和身体状态生成概率化预期,再拿感官反馈去校准。
你下一秒会看到什么、手伸出去会碰到什么,目标还在不在刚才那个位置,大脑全在提前算。
真实感官输入回来后,预测和现实一对比,差值就成了预测误差。误差推着内部模型往前更新。
拿AI领域的概念类比,大脑本身就在跑一套世界模型。
,大脑做的事很像,只不过人类这套系统天然和身体长在一起。视觉、视线、触觉、本体感觉、肌肉反馈、注意力、误差信号,全跑在同一条链路上。
具身智能想学的,恰恰是这个。
机器人要进入厨房、仓库、实验室、家庭这样的真实场景,光有视觉识别和动作模仿还不够。
真实世界会滑、会挡、会变、会突然打断任务。目标怎么选,动作什么时候启动,偏差出现后怎么修正,失败了怎么换策略,这些能力单靠一段视频学不到。
具身智能真正缺的,不是更像录像机的数据,是更像
摄像头拍到了手,但拍不到大脑
过去一年,ego-centric、human-centric数据成为具身智能的主流燃料。
机器人真机数据采集成本高、速度慢、设备贵,场景覆盖有限。
相比之下,人类第一视角数据的采集门槛低得多,一个人戴上相机做饭、整理桌面、开抽屉、拿工具,就能产出大量原始任务素材。
这类数据能记录环境里有什么,物体怎么变化,手和物体如何接触,任务最后有没有完成。对模型来说,这些都是真实世界操作的基础材料。
但第一视角视频有一个天然边界:
摄像头能看到手伸向杯子,却看不到
能看到杯子被拿起来,却看不到
能看到手指接触物体,却看不到
能看到任务成功或失败,却看不到
反馈误差怎样触发下一步修正
现有human-centric数据更像一个行为结果库,记录的是动作轨迹和任务结果。
具身智能真正需要学的东西,是
——目标如何被发现,注意力如何切换,意图如何形成,肌肉如何执行,反馈怎么改变动作。
如果大脑是一套预测式世界模型,训练数据就要尽可能记录这套模型的运行过程。不只是“人看到了什么、手做了什么”,还要覆盖“人如何预测、如何行动、如何反馈、如何更新”。
FaceMind脸谱心智想填的就是这个缺口。
这家公司由两位95后博士
创立,早期从端侧全模态模型切入,随后把研究重心转向
△脸谱心智Founder陆弘远