
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400">
撸猫撸出SOTA!3个00后2个月,造出史上最快流式音视频社交模型
速度快7倍,成本只有Veo 3的1/2000
鹭羽 发自 凹非寺 量子位 | 公众号 QbitAI
一觉醒来,AI的新潮流变成了
火速围观一下,刚刚全球流式音视频模型赛道闯进了一匹黑马,能力SOTA级,模型名字就叫
(MaineCoon)。
养过缅因猫的朋友都知道,这个品种有个外号叫「猫狗」,意思是几乎你走到哪儿,它就跟到哪儿,相当粘人,互动感MAX。
而模型MaineCoon和它几乎是如出一辙,不会一股脑生成完就跑,而是一直陪着你、follow你的状态,实时地往下走。
【此处无法插入视频,遗憾……可到量子位公众号查看~】
,效果就像是在和真人主播1V1视频对话,而且永远不会卡顿。
以上,这也是业界首次实现这个长度。
【此处无法插入视频,遗憾……可到量子位公众号查看~】
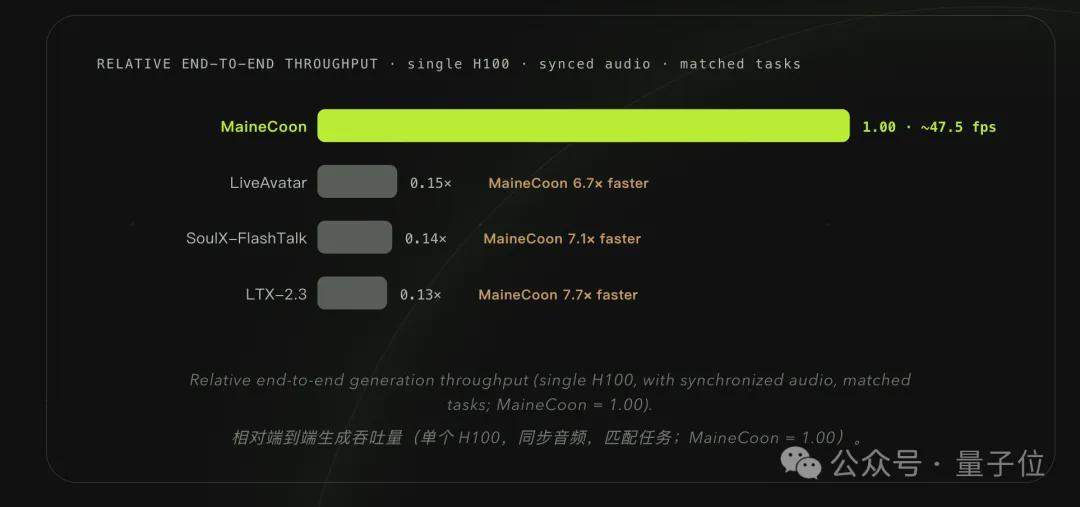
此外,MaineCoon的推理速度也很突出——
参数的大小,却能在单张H100上跑出47.5 FPS,
同赛道速度位居业界第一
;即使是在只有H100一半成本的推理卡RTX Pro 6000上,也能稳定保持30 FPS以上的实时运行速度。
假设我手里有一张GPU,用MaineCoon生成一条10秒的短视频,⾸帧将在3s以内出现,随后开始流式输出,新增prompt与实时输出无缝衔接,全程过渡丝滑自然。
成本直接被打下来,每秒成本控制在0.001美元以内。
如果在GPU占满的状态下,每秒推理更是仅需
,是Veo 3的1/2000、Seedance的1/560。
而这些,来自一家base中国的10人初创团队,名叫
几天前,他们刚刚在𝕏上发布了技术报告,就迅速收获多方关注,其中LTX官⽅也注意到了这家新面孔,并主动寻求合作。
话不多说,来看具体效果。
效果show time
其实MaineCoon和一般的音视频生成模型还不太一样,它首次将场景垂直落地在社交交互中。
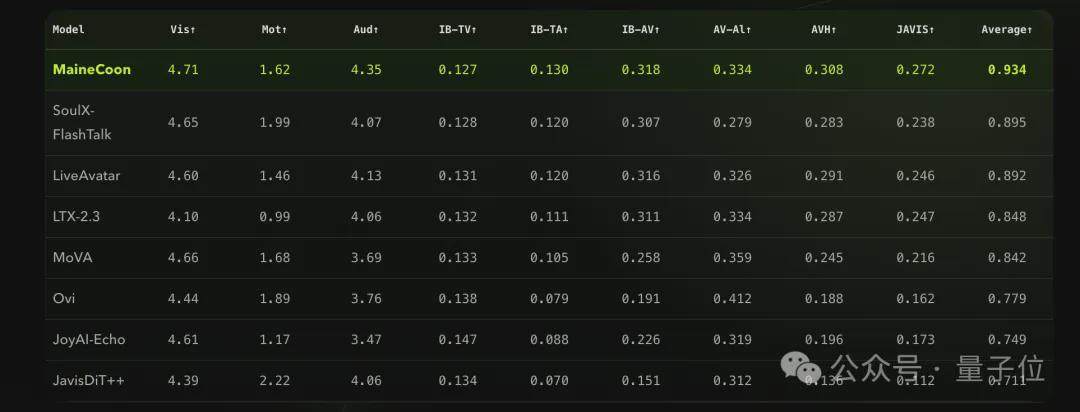
且看各家现有的生成模型卷到飞起,Benchmark表现一个赛一个亮眼,但依旧有硬伤:
要么速度太慢,要等完整生成后才能看到效果,根本没法实时,对创作者并不友好;要么做得了视频,却顾不上音频,音画永远分开走。
这类通用音视频模型更擅长模拟物理规律和场景叙事,天空中的云怎么飘、水面的光怎么反射,它们拿捏得很准,但一到人物表现上就屡屡翻车。
于是判断AI视频与否,大家总结出一条心照不宣的经验——
要做社交距离也不露怯的视频,关键在于人物细节是不是够自然,比如眼神的变化、嘴角的抽搐、说话的节奏等等,还要音画高度同步、生成过程中随时可切换指令。
难度系数拉满了,但这些细节才是决定活人感的关键。
瞄准的,正是这个被整个行业忽视掉的缺口。
具体来说,它做到了三件此前没有模型能同时做到的事。
这并非新鲜概念,最早ChatGPT一个字一个字往外蹦,就是流式输出。简单来说,就是让模型能够边看边生,推理到哪儿,就生成到哪儿。
但视频的一帧涉及到成千上万个像素,还要和音频在时间轴上精准对齐,和单纯文字流式生成的难度完全不在同一个量级上。
而且生成片段越小,就意味着每一帧能依赖的历史上下文越短,模型就更容易露馅。
MaineCoon则把这个单元极致压缩到了
,指令输出后1秒内就出首帧,低延迟和高质量两手抓。不止快了一点,更是生成方式的彻底改变。
比如下面模拟人物对话,初始Prompt要求人物语气平静且深思熟虑,结果无论是角色的面部肌肉走向,还是语气停顿,都精准遵循指令。